
Hello,
I work for an educational research project that makes online learning courses, and we need to scrape our courses for some of the content on each page because we didn't structure our databases to easily extract it from the XML.
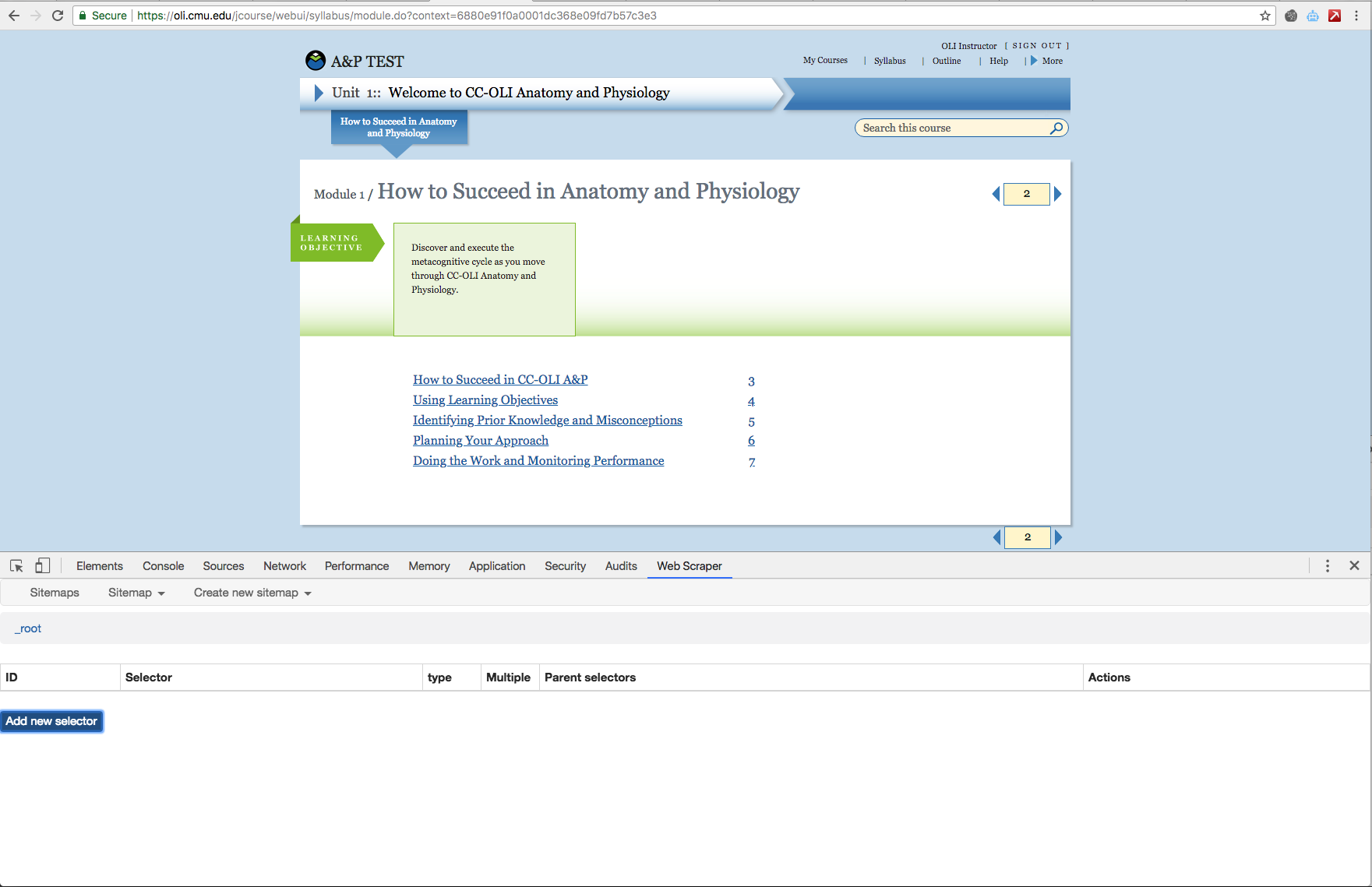
When I click "Add new selector" nothing happens, but it works on other pages. Is this because our pages are behind an authentication wall? Here is my plan:
Unit #: Title
Module #: Title
Learning Objective(s)
{next page}
That's all. Those are the only pieces of info I want to scrape and correlate, but I cannot create any selectors. Is this possible? Here is my starting URL and a screencap of the page:
https://oli.cmu.edu/jcourse/webui/syllabus/module.do?context=6880e91f0a0001dc368e09fd7b57c3e3
Thanks for your help in using this great tool!
Hal
Sitemap:
{id:"sitemap code"}