
Hi All
I am having problem with websraper and urgently need your help.
I am trying to scrape product description, in data preview , it shows description content, but when I try export data as csv, the description field in my csv imported file show “Null”
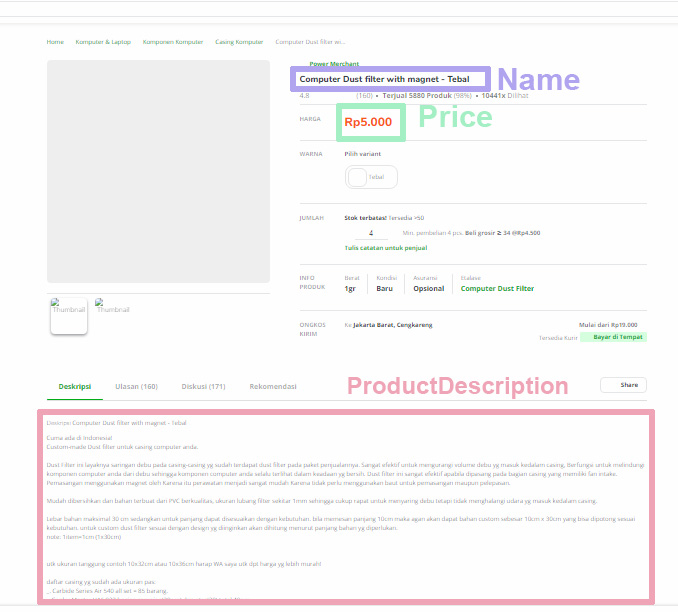
I am using the following sitemap to scrape the site using webscraper chrome plugin
{"_id":"computer1","startUrl":["https://www.tokopedia.com/search?st=product&q=computer&ob=5&page=1"],"selectors":[{"id":"productlink","type":"SelectorLink","parentSelectors":["_root"],"selector":"._2OBup6Zd a, a.anchor-overlay","multiple":true,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["productlink"],"selector":"h1.css-x7lc0h","multiple":false,"regex":"","delay":0},{"id":"price","type":"SelectorText","parentSelectors":["productlink"],"selector":"h3","multiple":false,"regex":"","delay":0},{"id":"productdescription","type":"SelectorText","parentSelectors":["productlink"],"selector":"p.css-1ngxow7-unf-heading","multiple":false,"regex":"","delay":0}]}
This is the metadata
Sitemap Name : computer1
Start URL : https://www.tokopedia.com/search?st=product&q=computer&ob=5&page=[1-2]
Scrape Parameter
Request interval (ms) :3000
Page load delay (ms) : 3000
The fields that I am scraping is only 3 which are Name, Price, and Producdescription
The CSV imported file show name,price fields are filled with data but Producdescription show "NULL"
even though in Data Preview show the content of the product description
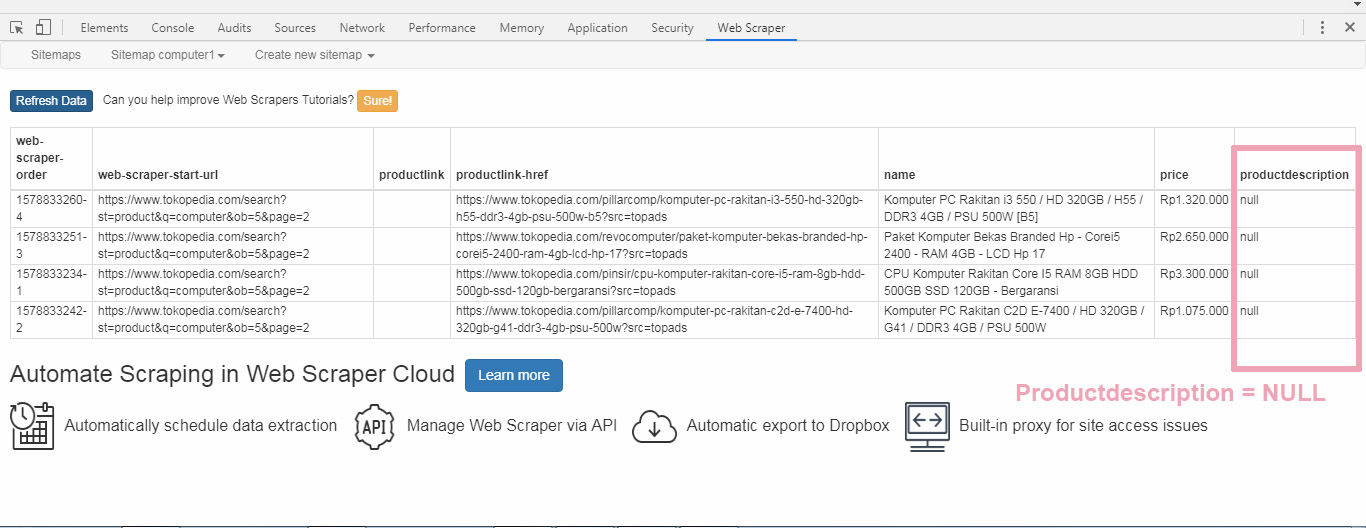
I have tried the following solution in the following threads but they don't work.
1.Anti-scraping measure
The excerpt
"Your selectors are too specific and are likely to fail. You've probably noticed that the site uses random-looking element names like sc-cLQEGU, sc-cLQEGU, sc-hORach etc. This is intentional and is probably an anti-scraping measure.
You'll need to spend a significant amount of time in the Chrome inspector and also have some knowledge of CSS selectors 1 to scrape such sites.
As an example, for "nomcontact", you can try:
span[class^="ant-avatar"] ~ div[class^="sc-"] > div[class^="sc-"]
This means, look for a div element which has a class that starts with "sc-" (ignores the random strings), which is a child of a div which also has a class that starts with "sc-", and which is preceded by a span element which has a class that starts with "ant-avatar"."
MY RESULT
I have tried using all kind of span tried to extract the productdescription content within the specified DIV. It doesn't work.
Even it does not show any content in Data preview.
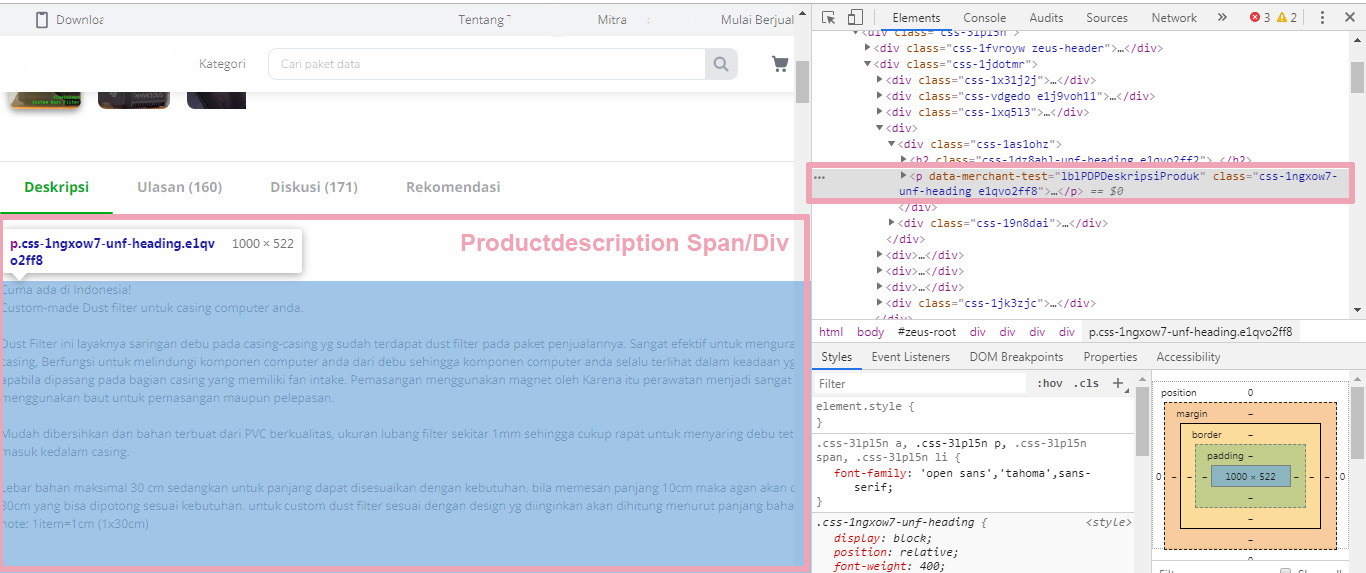
2.Page load delay not long enough
MY RESULT
I have setup Page load delay from 2000 ms to 5000 ms, productdescription still "NULL"
3.Scroller
MY RESULT
When I try to load the product
https://www.tokopedia.com/xinvicious/computer-dust-filter-with-magnet-tebal-9d01
I can see that productdescription need is loaded normally with no lazy loading or dynamically loaded
I don't see how adding scroller so that the webscraper scroll down all the way to bottom can help to fixed the null issue
Please help me guys. I am out of ideas already.
ps: I am sure this is an issue that is affected every users that use webscraper. How can we subscribe to paid version/cloud if the free one can not even extract product description

 after using numerous scraper like
after using numerous scraper like