Web Scraper version: 1.75.7
Chrome version: Version 122.0.6261.69 (Build officiel) (x86_64)
OS: Venture 13.6.3 (22G436)
Link to the site you were scraping:https://trafigura.wd3.myworkdayjobs.com/TrafiguraCareerSite?locationCountry=187134fccb084a0ea9b4b95f23890dbe
Sitemap : {"_id":"tradfigura","startUrl":["https://trafigura.wd3.myworkdayjobs.com/TrafiguraCareerSite?locationCountry=187134fccb084a0ea9b4b95f23890dbe"],"selectors":[{"id":"link","parentSelectors":["_root"],"type":"SelectorLink","selector":"a.css-19uc56f","multiple":true,"linkType":"linkFromHref"},{"id":"text","parentSelectors":["link"],"type":"SelectorText","selector":"a.css-19uc56f","multiple":true,"regex":""}]}
{id:"my sitemap"}
Log Information (Screen Record):
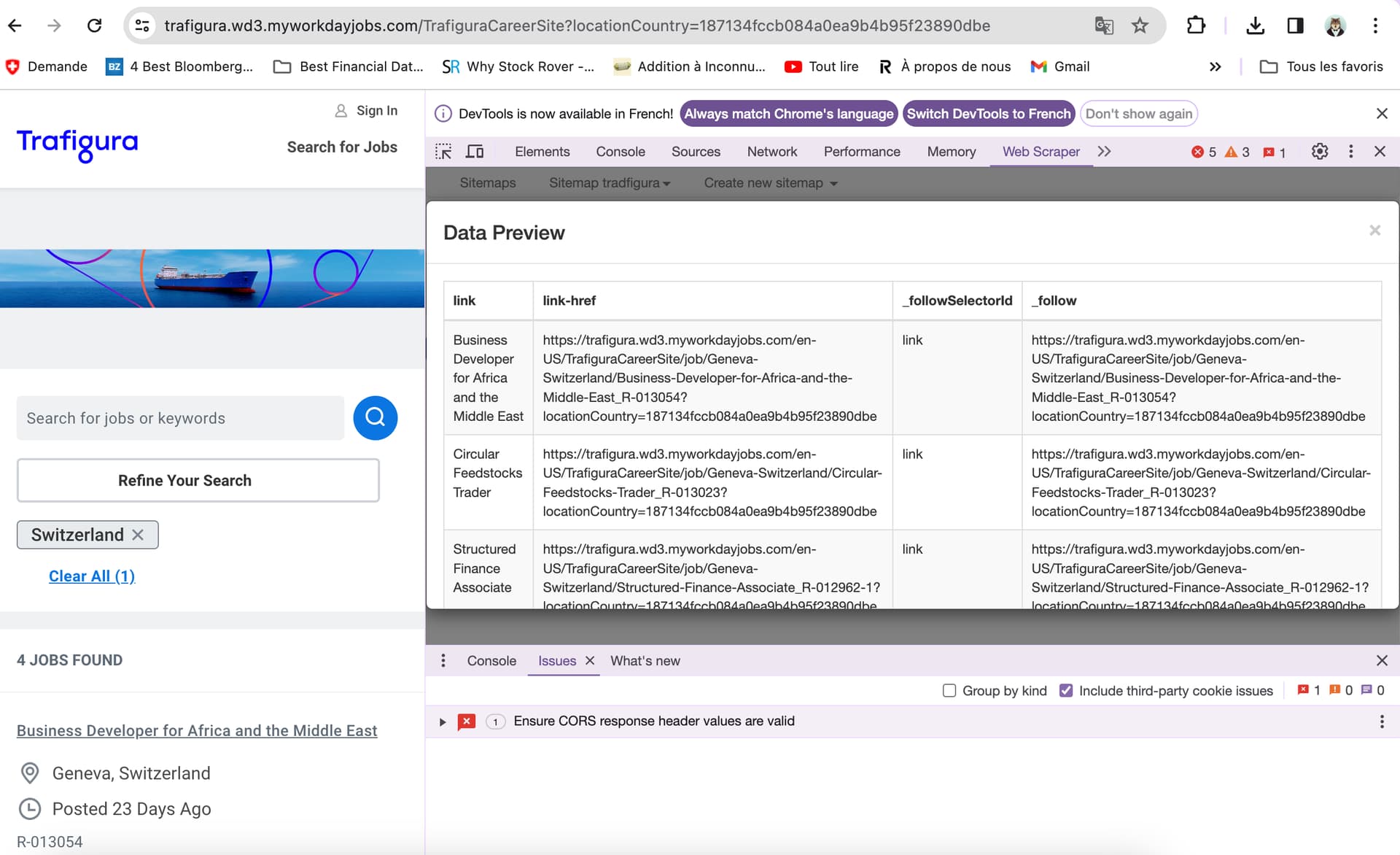
Hello,
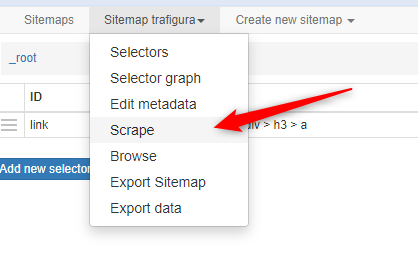
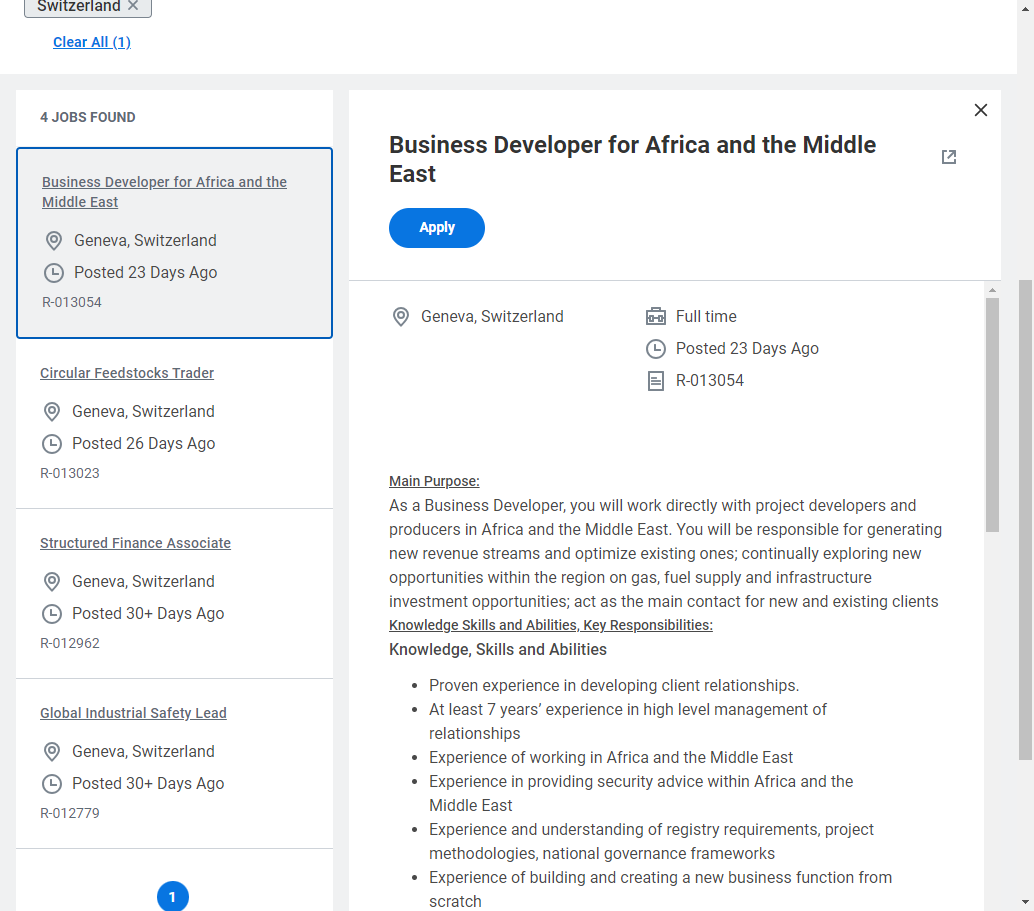
I am trying to scrape this page and extract the job offer. I tried many ways by using python with beautiful soup, then with scrapy and finally using your solution. It turned out that I got always the same issue with an empty output.
I assume there might be a problem of restriction but not really sure. I tried to use rotating proxies and different headers and user agent without success.
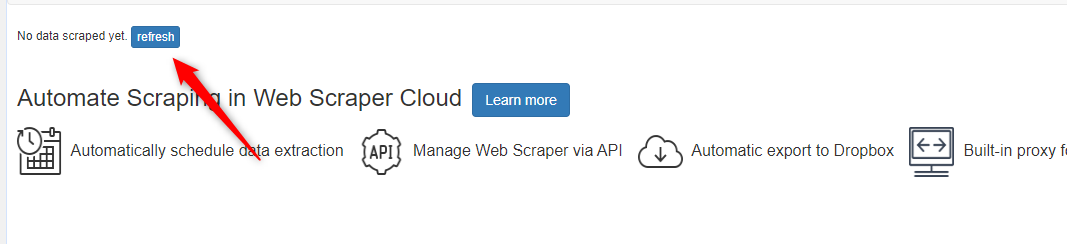
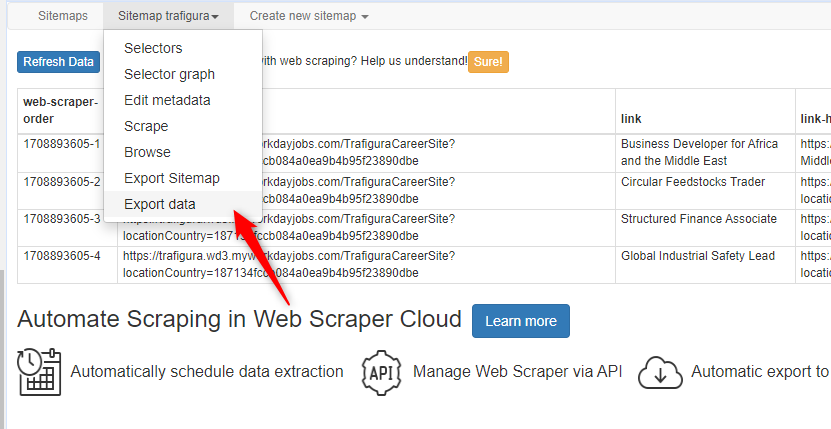
So I used your solution and I can have the data preview available like others but when scraped I got nothing in the csv file.
The only clue that I have is that it seemed that there is a problem of CORS response header.