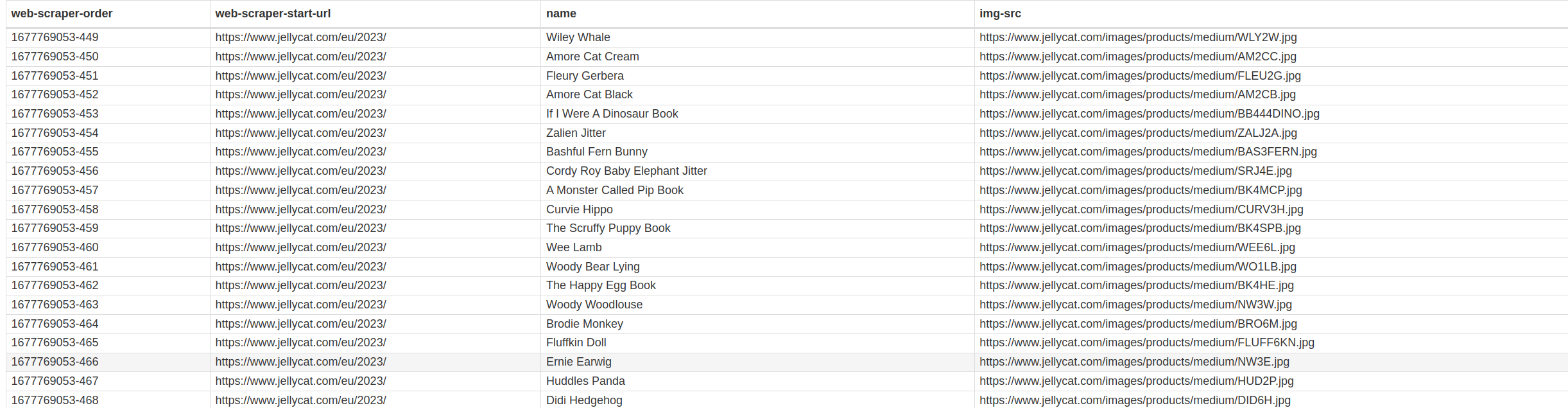
I don't know anything about webscaping but enlisted the assistance of an AI to write some scripts for me, we tried Python and Java scripts and both times it had issues finding elements on the page. I know they're populated by java (which was why I thought I'd try getting it to write a javascript). It's tried a few ways to detect the element, CSS, xpath but they all end the same way. I just want it to pull a list of all the products on this page (https://www.jellycat.com/2023) and put it in an excel file. This is what it's made so far:
const { Builder, By, Key, until } = require('selenium-webdriver');
const chrome = require('selenium-webdriver/chrome');
const excel = require('exceljs');
async function scrapeJellycat() {
const driver = await new Builder().forBrowser('chrome').build();
try {
await driver.get('https://www.jellycat.com/2023/');
await driver.wait(until.elementLocated(By.xpath('//*[@id="content"]/div[3]')), 10000);
const products = await driver.findElements(By.xpath('//*[@id="content"]/div[3]/div'));
const workbook = new excel.Workbook();
const worksheet = workbook.addWorksheet('Retired Jellycats');
worksheet.columns = [
{ header: 'Product Name', key: 'name', width: 30 },
{ header: 'Product Code', key: 'code', width: 15 },
{ header: 'Description', key: 'description', width: 50 },
];
for (let i = 0; i < products.length; i++) {
const name = await products[i].findElement(By.xpath('./div[2]/a')).getText();
const code = await products[i].findElement(By.xpath('./div[2]/div[1]')).getText();
const description = await products[i].findElement(By.xpath('./div[2]/div[2]')).getText();
worksheet.addRow({ name, code, description });
}
await workbook.xlsx.writeFile('C:/*****************/Jellycat/Retired-Jellycats.xlsx');
console.log('Scraping complete!');
} catch (error) {
console.log(error);
} finally {
await driver.quit();
}
}
scrapeJellycat();