Try this sitemap which will just scrape the first 5 pages:
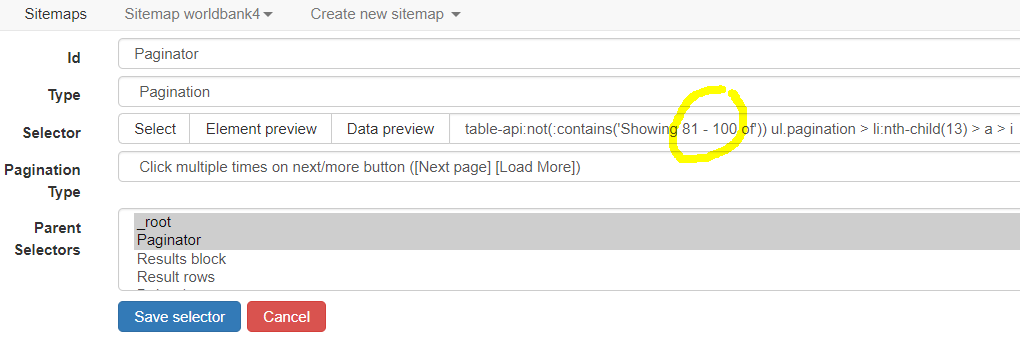
{"_id":"worldbank5","startUrl":["https://projects.worldbank.org/en/projects-operations/procurement?srce=both"],"selectors":[{"id":"Paginator","paginationType":"clickMore","parentSelectors":["_root","Paginator"],"selector":"table-api:not(:contains('Showing 81 - 100 of')) ul.pagination > li:nth-child(13) > a > i","type":"SelectorPagination"},{"id":"Results block","multiple":false,"parentSelectors":["_root","Paginator"],"selector":"div.paragraph > table","type":"SelectorElement"},{"id":"Result rows","multiple":true,"parentSelectors":["Results block"],"selector":"tbody tr","type":"SelectorElement"},{"id":"Desc","multiple":false,"parentSelectors":["Result rows"],"regex":"","selector":"td:nth-of-type(1)","type":"SelectorText"},{"id":"Country","multiple":false,"parentSelectors":["Result rows"],"regex":"","selector":"td[data-th='Country:']","type":"SelectorText"},{"clickActionType":"real","clickElementSelector":"tr:nth-of-type(1) td[data-th='Country:']","clickElementUniquenessType":"uniqueText","clickType":"clickOnce","delay":1000,"discardInitialElements":"do-not-discard","id":"Delay 1s","multiple":false,"parentSelectors":["Results block"],"selector":"tr:nth-of-type(1) td[data-th='Country:']","type":"SelectorElementClick"},{"id":"Project Title and Link","linkType":"linkFromHref","multiple":false,"parentSelectors":["Result rows"],"selector":"[data-th='Project Title:'] a","type":"SelectorLink"},{"id":"Notice Type","multiple":false,"parentSelectors":["Result rows"],"regex":"","selector":"td[data-th='Notice Type:']","type":"SelectorText"},{"id":"Language","multiple":false,"parentSelectors":["Result rows"],"regex":"","selector":"td[data-th='Language:']","type":"SelectorText"},{"id":"Pub Date","multiple":false,"parentSelectors":["Result rows"],"regex":"","selector":"td[data-th='Published Date:']","type":"SelectorText"}]}
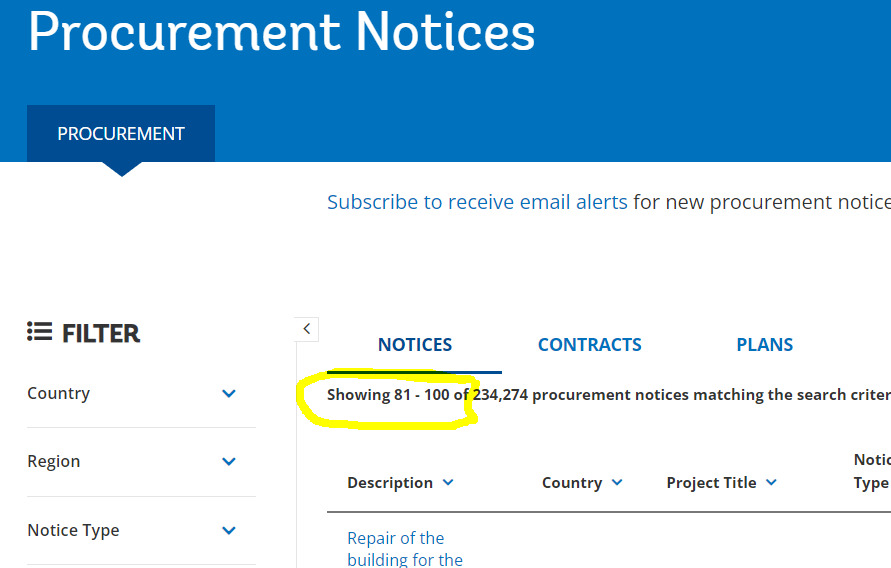
You can change the numbers in Paginator selector. In this example, it is "Showing 81 - 100 of" which will make WS stop at page 5 (each page contains 20 notices, so 5 x 20 = 100):
You can change these numbers to match the status text which changes with each new page. The example below shows the status text for page 5. You just need to do a bit of math to figure out the status numbers for the page you want to stop at. When WS encounters this status text, it will not click the next page and the scraper stops.
I highly recommend you run this 5-page example first, to confirm that it really works for you (and that it is stopping at page 5). Also note that this site seems to have a lot of duplicate entries. You can remove those with Excel but that means you may not get the number of results you expected.