
When I use "Sitemap.xml Links" selector on quite large sitemap (1.5mb), it shows me the correct links in the data preview but when I run the scraper it doesn't forward me to the sites. Any ideas? Foung Url Regex and Minimum priority can't be the issue
@rosetalbaum Hi! Could you, please, provide the sitemap you are referring to? Please, note that the scraper can only use a certain number of XML files before exceeding the 25MB start URL limit per single sitemap.
It’s a single XML file that is 1.5mb. I tried smaller sitemap.xml files and they work fine
@ViestursWS do you have any ideas? I'm very fond of https://webscraper.io/ and really want to avoid writing a scraper from scratch in JS or Python...
For instance this sitemap:
{"_id":"test-sitemap","startUrl":["https://webscraper.io/"],"selectors":[{"id":"sitemap","parentSelectors":["_root"],"sitemapXmlMinimumPriority":"0.0","sitemapXmlUrlRegex":"","sitemapXmlUrls":["https://webscraper.io/sitemap.xml"],"type":"SelectorSitemapXmlLink"}]}
It opens the start page and stops immediately after
Edit: Might be something with my computer though because a sitemap that I know worked yesterday has same behavior now
@rosetalbaum Hello, it does not appear as if the xml.selector would have any child selectors. In such a setup it would serve only as the sitemap.xml link extractor.
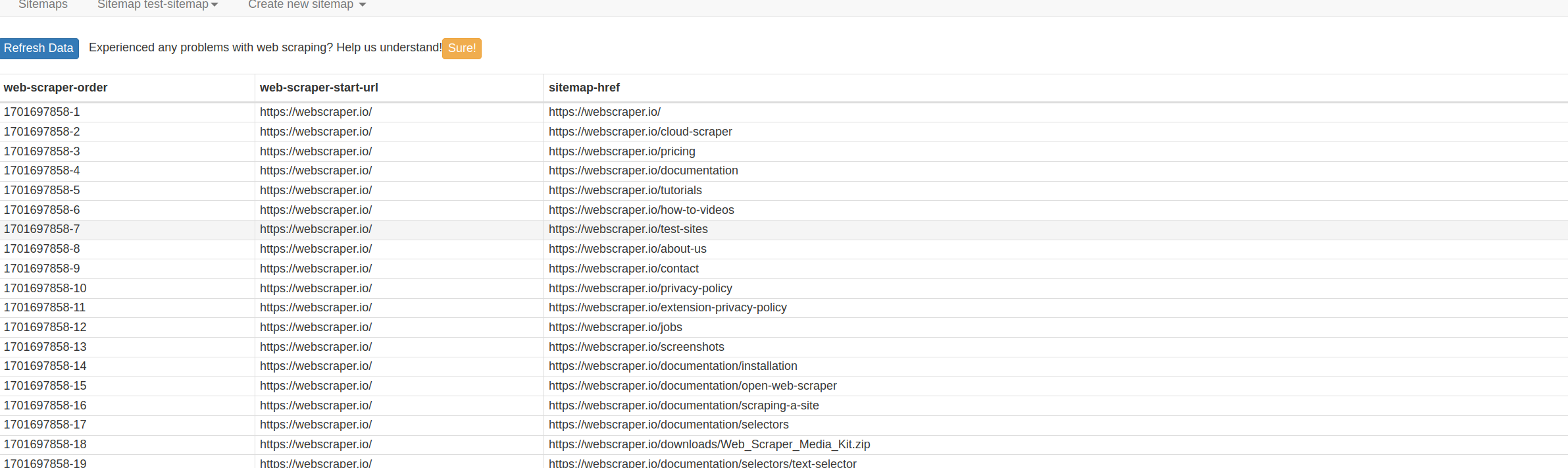
If you are looking to extract anything that could be located within the targeted URLs you will have to create additional selectors, such as H1 in this case:
{"_id":"test-sitemap","startUrl":["https://webscraper.io/"],"selectors":[{"id":"sitemap","parentSelectors":["_root"],"sitemapXmlMinimumPriority":"0.0","sitemapXmlUrlRegex":"","sitemapXmlUrls":["https://webscraper.io/sitemap.xml"],"type":"SelectorSitemapXmlLink"},{"id":"test","multiple":false,"parentSelectors":["sitemap"],"regex":"","selector":"h1","type":"SelectorText"}]}