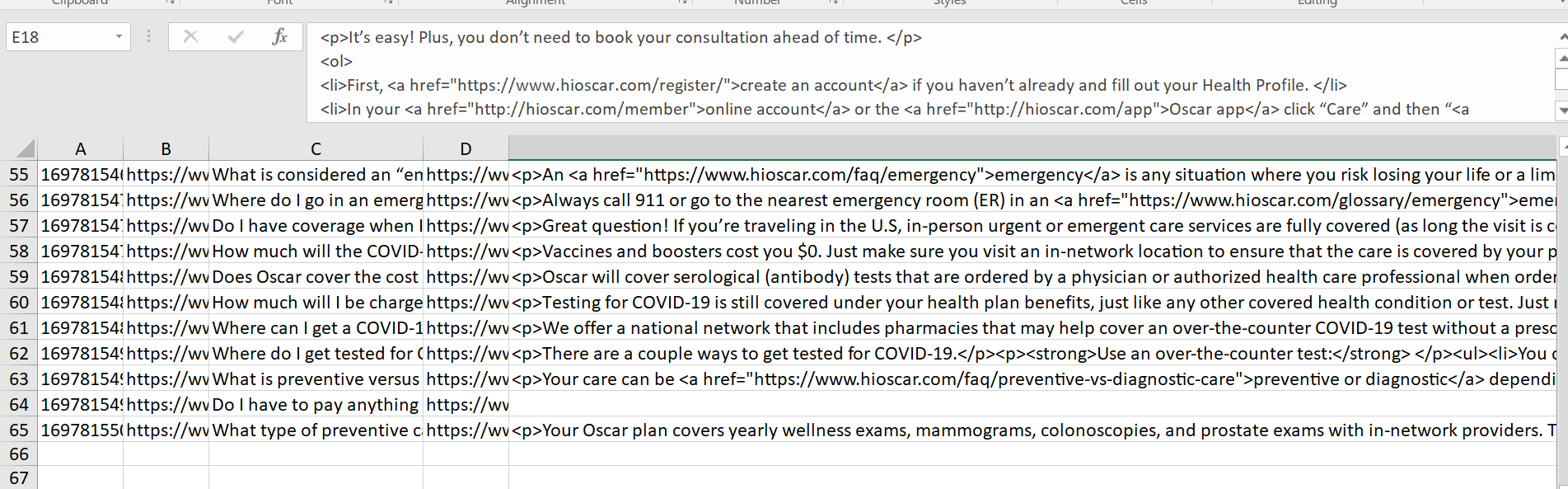
Hi, I am trying to scrape data from the below website. But even after creating a proper sitemap I am getting insufficient data. It seems it is skipping some data or giving us interleaved data.
- I need suggestions on why this is happening ?
- Is there a way to resolve it?
- Do we have a list of websites or website structures where https://webscraper.io/ doesn't work properly?
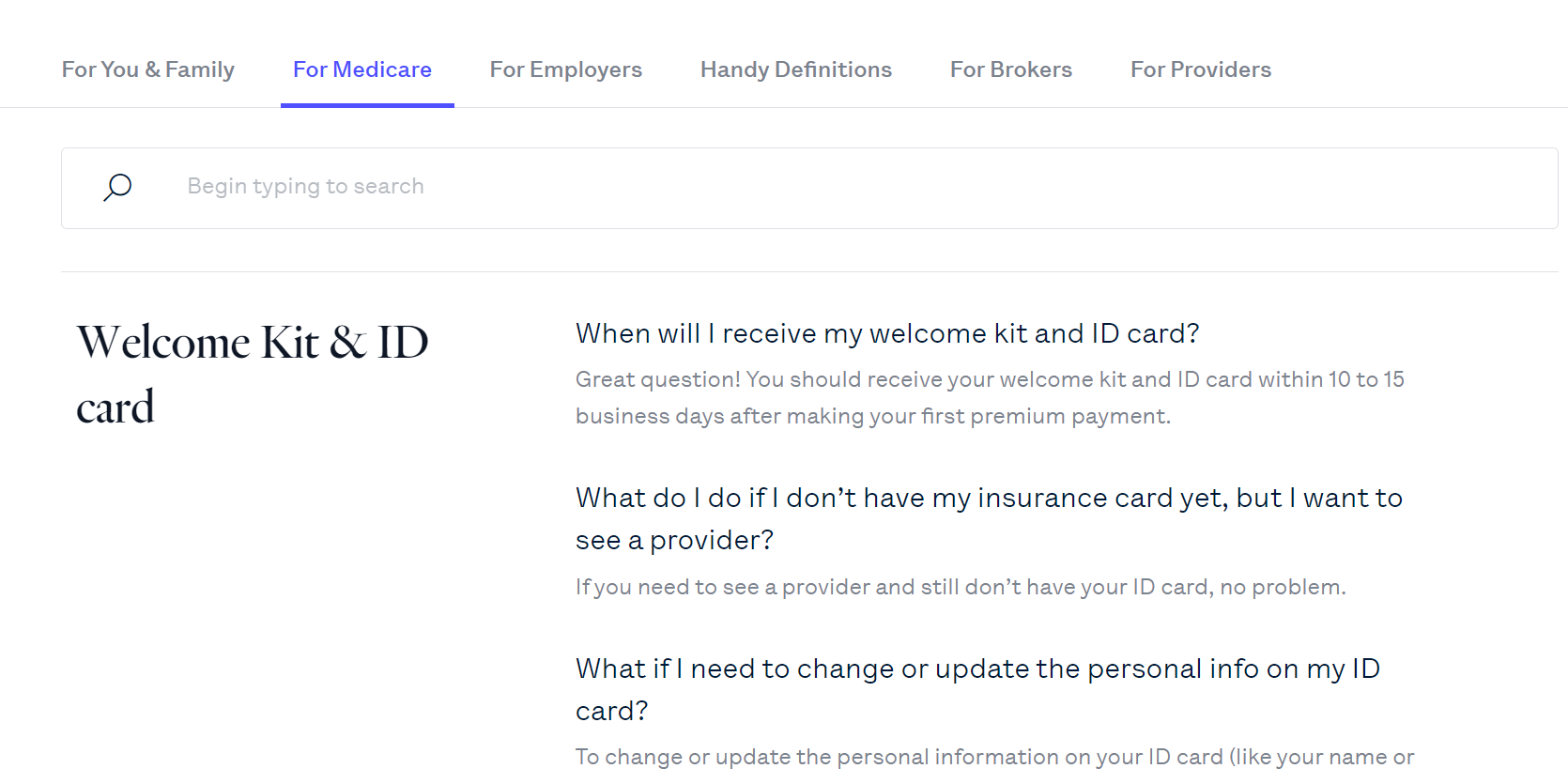
Url: https://www.hioscar.com/faq#for-medicare
In this website, I need only data from medicare section.
Sitemap:
{"_id":"hioscar","startUrl":["https://www.hioscar.com/faq#for-medicare"],"selectors":[{"id":"link","parentSelectors":["_root"],"type":"SelectorLink","selector":"a.h-219IrFXyCMpob8eCiWjqAa","multiple":true,"linkType":"linkFromHref"},{"id":"data","parentSelectors":["link"],"type":"SelectorText","selector":"div.h-10C2yOzK-Pu-3erMTexkfi","multiple":true,"regex":""}]}