
Describe the problem.
Hello, I am currently trying to scrape a news website -each element contains a few items such as county, source and deal value - the problem is that they not present in all articles - which leads to them being a different 'nth of type (n)' each time. The only way of recognising these text is the text preceding the actual text I want. Is there a way to only scrape the data if it contains "Source" for instance? Thanks
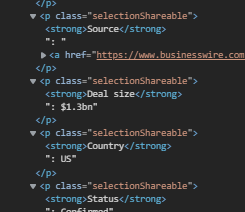
Url: Media mergers news: Tracker on all latest news media M&A (pressgazette.co.uk)

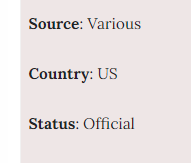
The ideal output is 4 columns - source, deal value, country and status - each with the text inside associated with the correct category (i.e source, country) Thank you!
{"_id":"press_gazzete","startUrl":["https://pressgazette.co.uk/media-mergers-news-tracker/"],"selectors":[{"id":"elem","parentSelectors":["_root"],"type":"SelectorElement","selector":"td","multiple":true,"delay":0},{"id":"date","parentSelectors":["elem"],"type":"SelectorText","selector":"> strong","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["elem"],"type":"SelectorText","selector":"strong span","multiple":false,"delay":0,"regex":""},{"id":"body","parentSelectors":["elem"],"type":"SelectorText","selector":"parent","multiple":false,"delay":0,"regex":""},{"id":"author","parentSelectors":["elem"],"type":"SelectorText","selector":"em span","multiple":false,"delay":0,"regex":""},{"id":"full html","parentSelectors":["elem"],"type":"SelectorHTML","selector":"parent","multiple":false,"regex":"","delay":0}]}