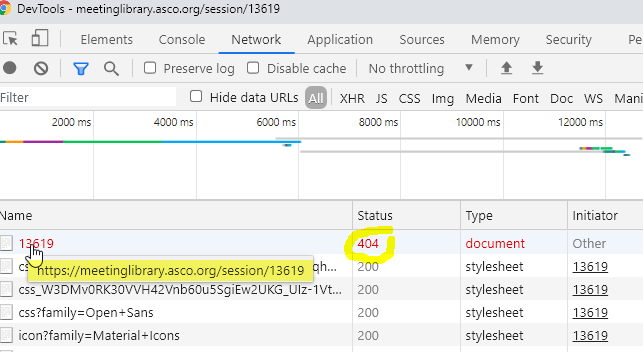
Hi everyone, I'm running into an unusual issue with my scrape of what "should" be simple pulling of text. I want an organized listing of abstract titles from the indicated website. In the past, I've been able to do this with relative ease, since this website doesn't use unusual pagination or lazy loading, as far as I can tell. However, this year, there is no output, and I get no notification that the scrape has finished, no matter what page load and request intervals I specify (I've tried between 2000 and 100,000 ms) in the test that I've built out below.
A few details about the issue:
-
If I preview data on the test page, things look fine. It IS just text, after all, and I've rendered the site. However, I get no output when scraping just this page. When the scraper is running, I do see the rendered text on the page, and my delays are long enough to sit there, watch, and verify that everything is loading correctly in the popup window. Other people experiencing the "data preview working, final output is not" issues seem to be related to lazy loading, and adjusting delays works well for them. Unfortunately, I could not find an issue that mirrors mine closely enough to assist me this time.
-
After the specified delay, the popup window closes with no indication that the scrape finished. I don't see any errors, of course, but it would appear that something is going wrong.
-
Webscraper IS working for me to do similar tasks on other websites, so it doesn't appear to be an issue inherent to Webscraper itself
Url: https://meetinglibrary.asco.org/session/13619
Sitemap:
{"_id":"test","startUrl":["https://meetinglibrary.asco.org/session/13619"],"selectors":[{"id":"Abstract Title","type":"SelectorText","parentSelectors":["_root"],"selector":"div.session-presentation:nth-of-type(n+3) .record__title span","multiple":true,"regex":"","delay":0},{"id":"Author","type":"SelectorText","parentSelectors":["_root"],"selector":"div:nth-of-type(n+4) .record__meta div.record__ellipsis","multiple":true,"regex":"","delay":0},{"id":"Abstract Number","type":"SelectorText","parentSelectors":["_root"],"selector":"div:nth-of-type(n+5) .record__meta > span","multiple":true,"regex":"","delay":0}]}
Thank you, everyone! I know this type of issue has been flagged previously, but they always seem to be with respect to other more complicated scrapes. I haven't run into a site where I can't pull ANY text at all. I can't even scrape elements that are more fixed on the website, like the banner.
Any assistance would be greatly appreciated! Thank you very much!