Hello,
I work for a call center that requires us to track our own time. I have tried creating a scrapper with Excel but ran into issues.
I have made a successful scrapper with this but have a question I can't seem to find the answer for. Currently, my scrapper goes to my closed cases and extracts the amount of time I was on a call as that's what I get paid off of. This is great for things that I closed but doesn't help with things that I may have handed off to someone else that don't appear in my closed cases.
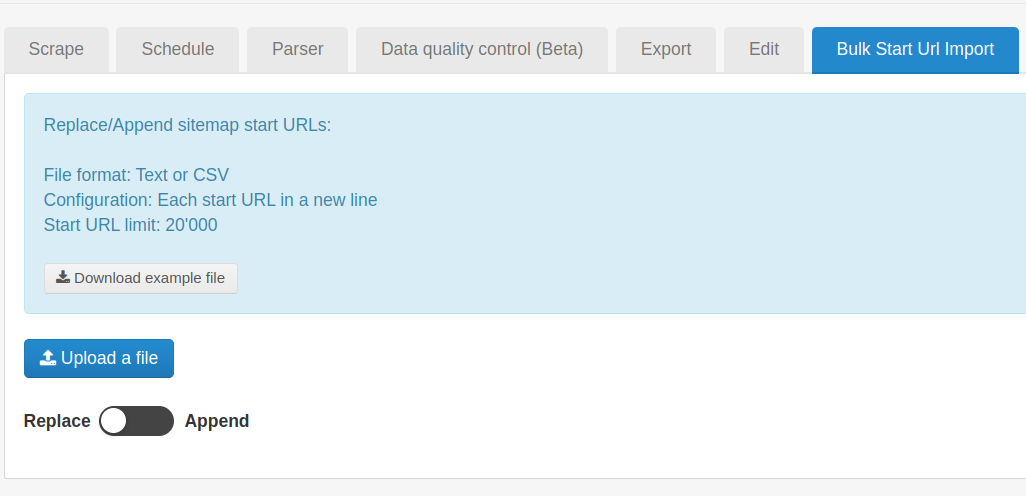
What I'm looking to do is the URL is standard and only the last 6 digits change for the case number. Is it possible for me to give the scrapper a list of Case numbers it can run through and then extract the relevant data for me? Everything else I want to do I was able to accomplish with my Proof of Concept, now I just need to figure out how to feed it the case numbers so it will scrap from those specific cases.
The url is: "//xxxx.xxxx.net/Case/CaseOverview?caseid=" then after the "=" I would just have it load in the 6 digit case numbers either from a text or excel sheet and extract to a Excel sheet and format from there.