Describe the problem :
Hello, I'm trying to scrape a website (http://www.annuaire-des-mairies.com) to get the information of all the town halls of France.
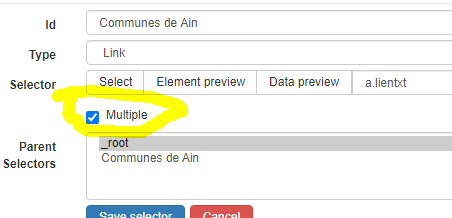
I create all the selector as requested but each time I launch the scraping my file is only half completed.
Someone would like to explain me why it doesn't work?
Thank you so much for your help !!
Url: http://www.annuaire-des-mairies.com
Sitemap:
{id:"sitemap code"}
{"_id":"mairieain","startUrl":["http://www.annuaire-des-mairies.com/ain.html"],"selectors":[{"id":"Communes de Ain","type":"SelectorLink","parentSelectors":["_root"],"selector":"a.lientxt","multiple":false,"delay":0},{"id":"adresse mairie","type":"SelectorText","parentSelectors":["Communes de Ain"],"selector":"section.well:nth-of-type(2) div","multiple":true,"regex":"","delay":0},{"id":"téléphone","type":"SelectorText","parentSelectors":["Communes de Ain"],"selector":"tr:contains('Numéro de téléphone de la mairie') td:nth-of-type(2)","multiple":true,"regex":"","delay":0},{"id":"fax","type":"SelectorText","parentSelectors":["Communes de Ain"],"selector":"tr:contains('Numéro de télécopie de la mairie') td:nth-of-type(2)","multiple":true,"regex":"","delay":0},{"id":"email","type":"SelectorText","parentSelectors":["Communes de Ain"],"selector":"tr:contains('Adresse Email') td:nth-of-type(2)","multiple":true,"regex":"","delay":0},{"id":"site web","type":"SelectorText","parentSelectors":["Communes de Ain"],"selector":"tr:contains('Adresse Email') td:nth-of-type(2)","multiple":true,"regex":"","delay":0}]}