Describe the problem:
I have used it before and it works. However, starting today, the webscraper of the own URL doesn't work.
Here's my work flow:
-
- I set "Page load delay " to 4000ms
-
- I initiate a search
-
- Then I mannually choose and click to the web page that I think relevant
-
- After clicking into the correct page, it scrape the book name, authors, usering rates and the URL of the correct page
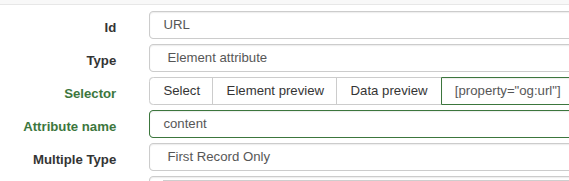
But now , the URL using " [rel="canonical"]" doesn't work anymore in this site.
Any workaround please?
Sitemap:
{"_id":"Goodreads-w39","startUrl":["Search results for "糖質疲労","https://www.goodreads.com/search?q=The" (showing 1-0 of 0 books) Crowd: A Study of the Popular Mind","Search results for "Klartext:" (showing 1-10 of 511 books) Sagen, was Sache ist. Machen, was weiterbringt","Search results for "Dinner" (showing 1-10 of 39722 books) with Darwin: Food, Drink, and Evolution","Search results for "State" (showing 1-10 of 1229268 books) of Terror","Search results for "Cannibal" (showing 1-10 of 4134 books) Capitalism","Search results for "Peak" (showing 1-10 of 28315 books) Mind: Find Your Focus, Own Your Attention, Invest 12 Minutes a Day","Search results for "The" (showing 1-0 of 0 books) Manager%E2%80%99s Handbook: Five Simple Steps to Build a Team, Stay Focused, Make Better Decisions, and Crush Your Competition"],"selectors":[{"id":"Link","parentSelectors":["_root"],"type":"SelectorLink","selector":"[rel="canonical"]","multiple":false,"linkType":"linkFromHref"},{"id":"Book-name","parentSelectors":["_root"],"type":"SelectorText","selector":"h1","multiple":false,"regex":"","multipleType":"singleColumn"},{"id":"Rating","parentSelectors":["_root"],"type":"SelectorText","selector":".RatingStatistics__interactive div.RatingStatistics__rating","multiple":false,"regex":"","multipleType":"singleColumn"},{"id":"Ratings-count","parentSelectors":["_root"],"type":"SelectorText","selector":".RatingStatistics__interactive span[data-testid='ratingsCount']","multiple":false,"regex":"","multipleType":"singleColumn"}]}