
Hi,
Cannot scrape phone numbers from the site.
Selected Element Attribute, and from site's Elements preview, found the "phone-content" is storing full phone info but when selected, data output is still NULL.
Could you help me figuring out how to extract full numbers from the site as well emails and website urls?
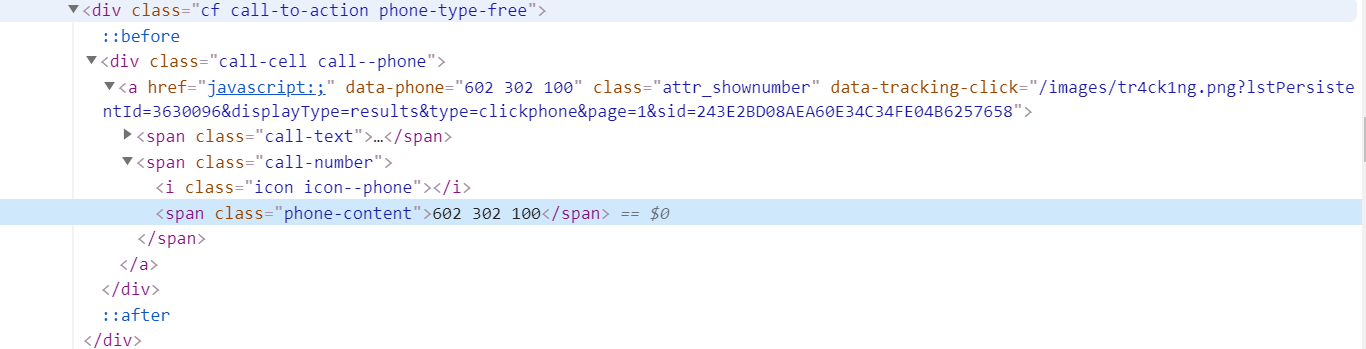
Url: https://www.pkt.pl/szukaj/geodezja/warszawa
Sitemap:
{"_id":"pkt_geodezja","startUrl":["Najlepszy geodeta w lokalizacji warszawa"],"selectors":[{"id":"name","type":"SelectorText","parentSelectors":["_root"],"selector":".company name • Geodezja • Geodeci • pkt.pl a","multiple":true,"regex":"","delay":0},{"id":"phone","type":"SelectorElementAttribute","parentSelectors":["_root"],"selector":"span.call-text","multiple":true,"extractAttribute":"phone-content","delay":0}]}
