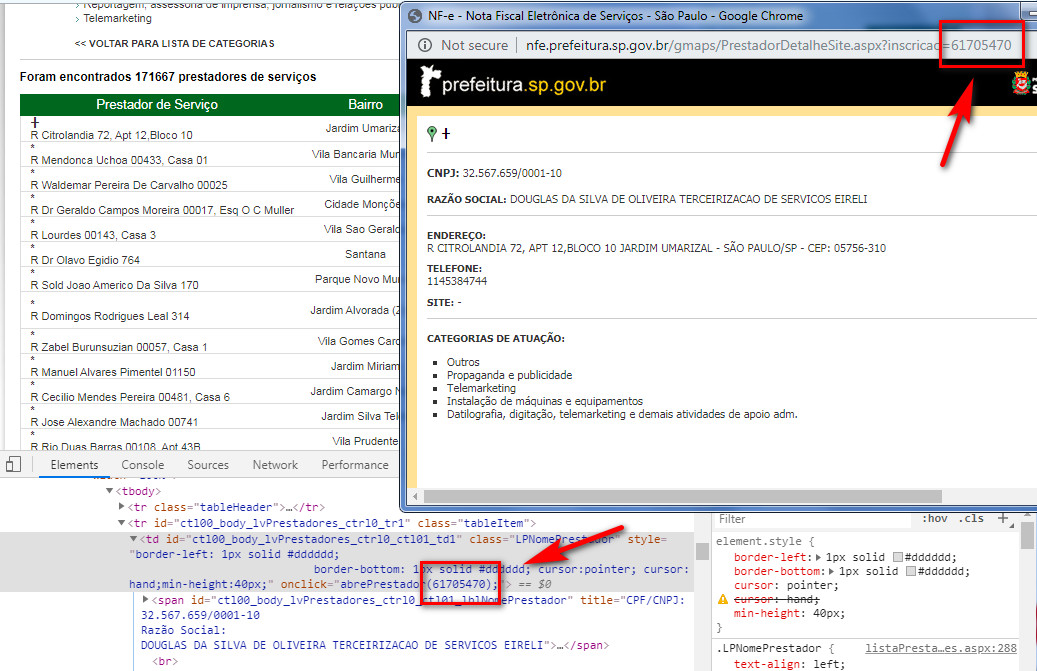
Describe the problem.
I have an issue with a specific page that I can't scrape it. I believe is too old that's why I'm experiencing problems which are:
Get into the main URL,
Url: https://nfe.prefeitura.sp.gov.br/publico/listaPrestadores.aspx
and after that, I need to extract the information below:
E.g.,
CNPJ: 19.910.685/0001-31
RAZÃO SOCIAL: MARMORARIA PEDRAS MATRIZ LTDA ME
ENDEREÇO: AV ENGENHEIRO ARMANDO DE ARRUDA PEREIRA 02912 JABAQUARA - SÃO PAULO/SP - CEP: 04308-001 TELEFONE: 1129258390 SITE: -
and the path to get there is:
bairrotype:jabaquara/click:jabaquara
I need all information that are in cnpj, razão social, endereço, cep, telefone and site.
The website is very old I guess that's the problem.
If anyone helps me out a really appreciate that.
Sitemap:
{id:"sitemap code"}