Hello viestrus!
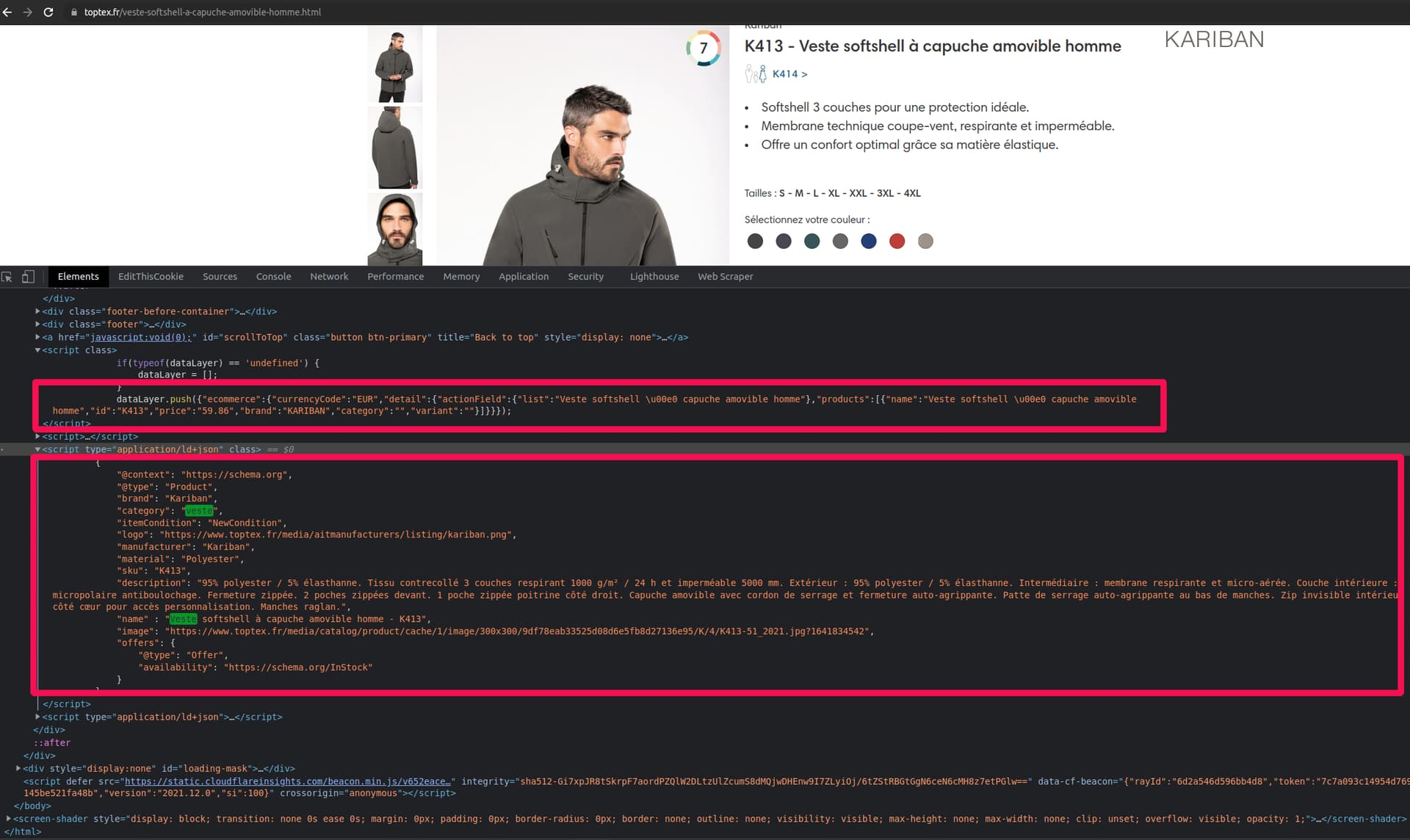
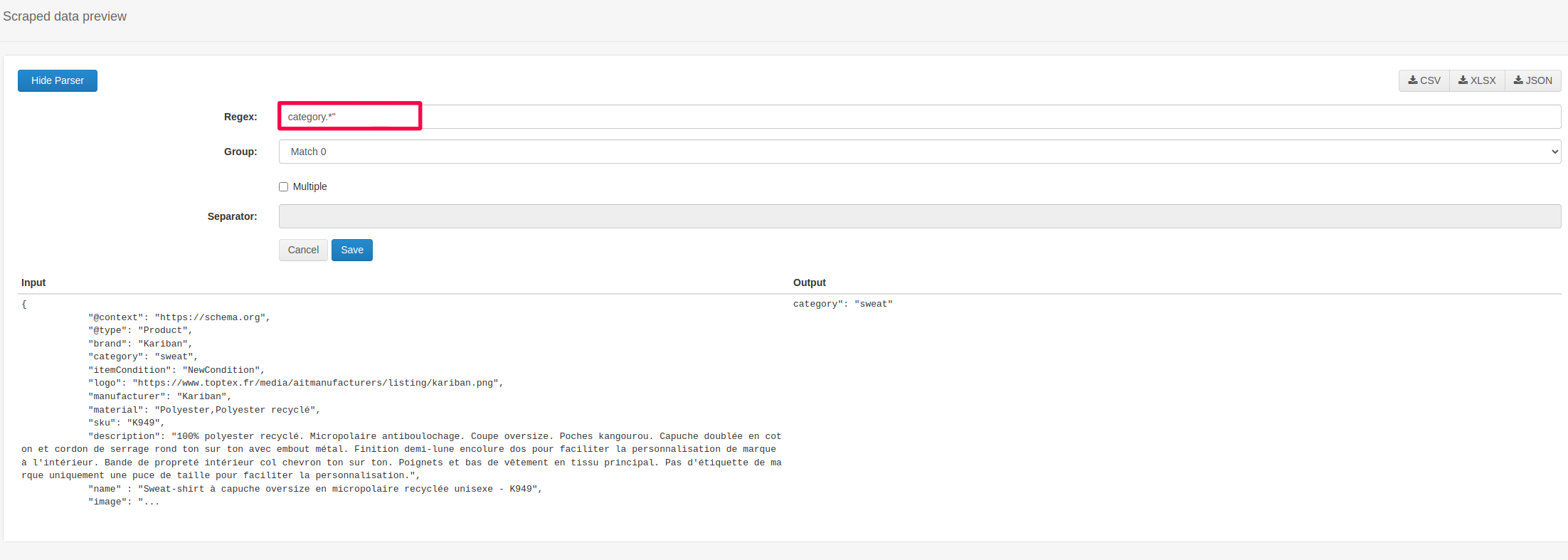
in fact it always gives me the same category on all products.
I think that some of the product sheets (new products) in the general page here, do not have an breacrump link:
https://www.toptex.fr/vetements.html
by creating a new sitemap that uses the megamenu, the breacrump remains empty anyway, while the previews are ok
{"_id":"toptexrootmenu","startUrl":["https://www.toptex.fr/vetements.html"],"selectors":[{"delay":0,"id":"menu","multiple":true,"parentSelectors":["_root"],"selector":".nav-1 a.level0.has-children, .nav-1-1 a.level1, .nav-1-1 li.level3:nth-of-type(n+2) a","type":"SelectorLink"},{"delay":0,"id":"bloc","multiple":true,"parentSelectors":["menu"],"selector":"a.product-image","type":"SelectorLink"},{"delay":0,"id":"breacrump","multiple":false,"parentSelectors":["bloc"],"regex":"","selector":"div.breadcrumbs","type":"SelectorText"},{"delay":0,"id":"name","multiple":false,"parentSelectors":["bloc"],"regex":"","selector":"h1","type":"SelectorText"}]}