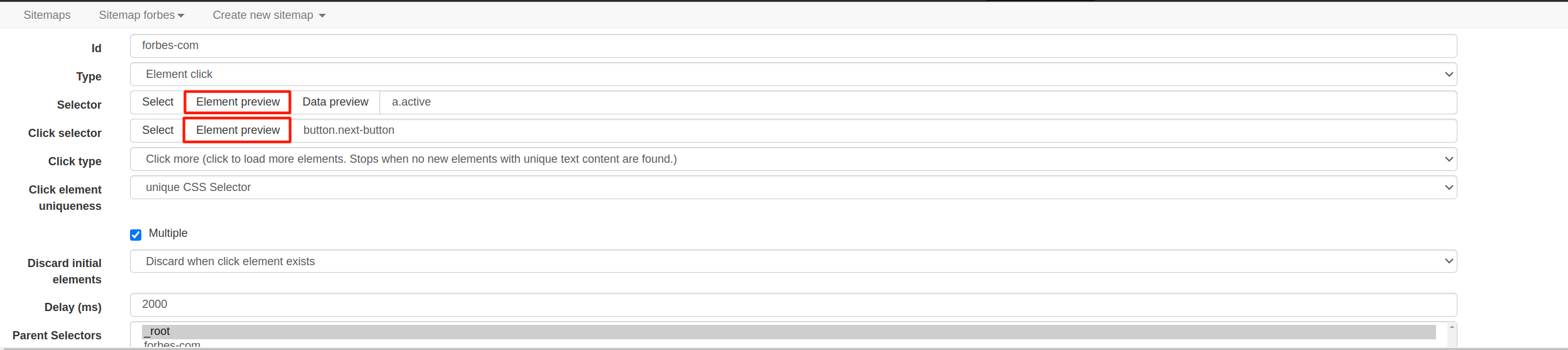
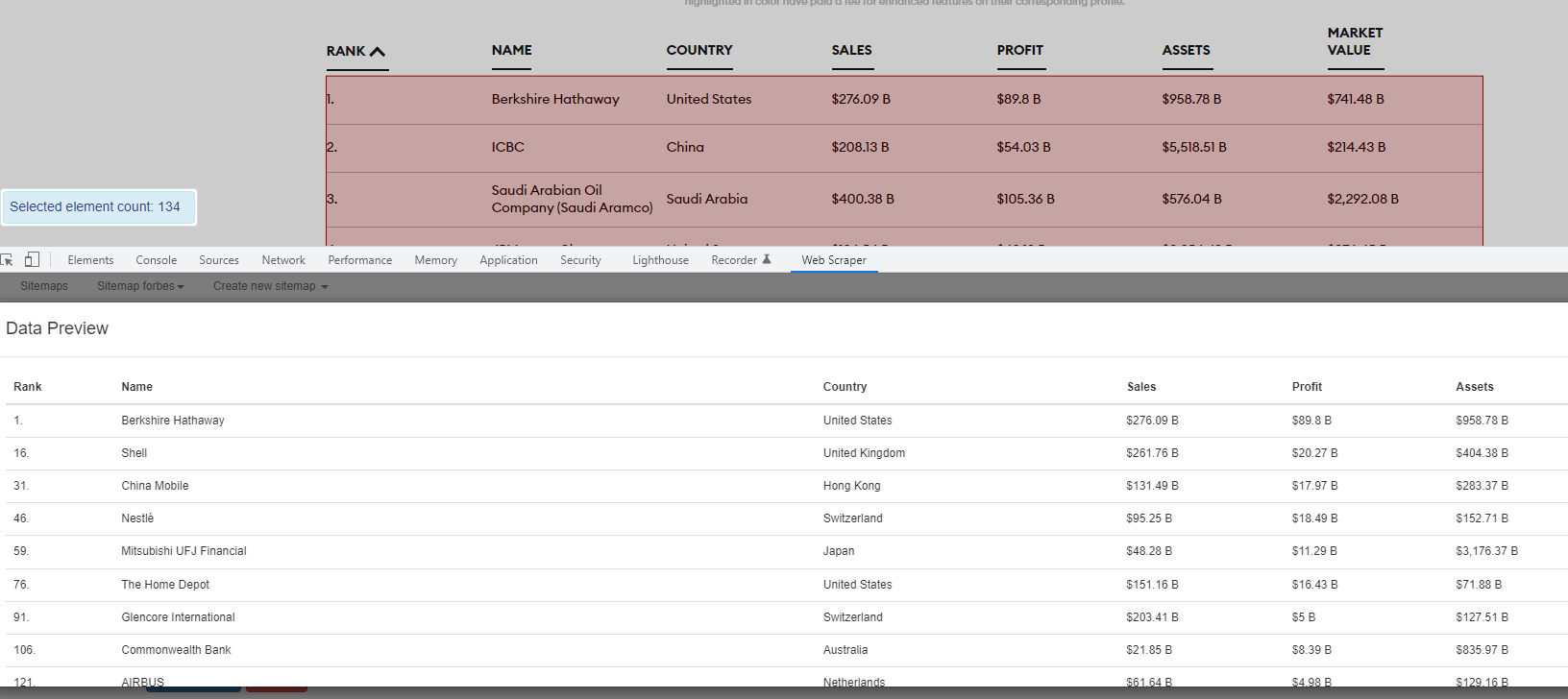
I am trying to scrape Forbes 2000 companies list using the code provided in forum concering the billionaires list.
Unfortunatley the site seems to be structured slightly different. There are blocks of entries and the query returns only the first entry of each block. Rest works fine. Can somebody help?
Greatly appreciated, thanks!
Url: The Global 2000 2022
Sitemap:
{"_id":"forbes","startUrl":["https://www.forbes.com/lists/global2000/"],"selectors":[{"clickElementSelector":"[xmlns] path","clickElementUniquenessType":"uniqueCSSSelector","clickType":"clickOnce","delay":2000,"discardInitialElements":"discard-when-click-element-exists","id":"forbes-com","multiple":true,"parentSelectors":["_root"],"selector":"div.table:nth-of-type(n+1)","type":"SelectorElementClick"},{"delay":0,"id":"Rank","multiple":false,"parentSelectors":["forbes-com"],"regex":"","selector":"div.rank","type":"SelectorText"},{"delay":0,"id":"Name","multiple":false,"parentSelectors":["forbes-com"],"regex":"","selector":"div.organizationName","type":"SelectorText"},{"delay":0,"id":"Country","multiple":false,"parentSelectors":["forbes-com"],"regex":"","selector":"div.country","type":"SelectorText"},{"delay":0,"id":"Sales","multiple":false,"parentSelectors":["forbes-com"],"regex":"","selector":"div.revenue","type":"SelectorText"},{"delay":0,"id":"Profit","multiple":false,"parentSelectors":["forbes-com"],"regex":"","selector":"div.profits","type":"SelectorText"},{"delay":0,"id":"Assets","multiple":false,"parentSelectors":["forbes-com"],"regex":"","selector":"div.assets","type":"SelectorText"},{"delay":0,"id":"Value","multiple":false,"parentSelectors":["forbes-com"],"regex":"","selector":"div.marketValue","type":"SelectorText"}]}