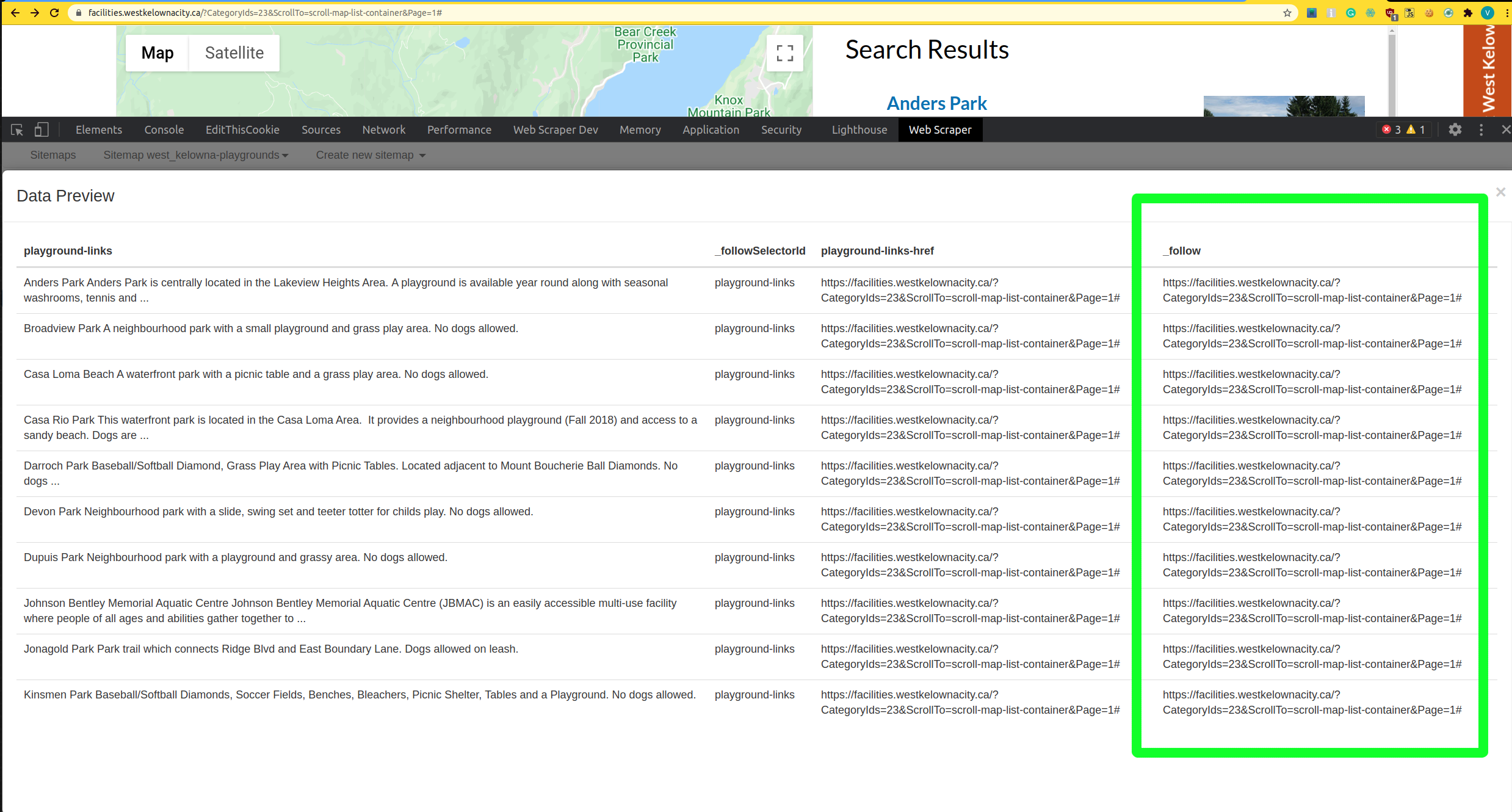
I am having troubles scraping this website.
I seem to be able to follow the pagination, but the detailed link request is only selecting the first entry of each page.
As well, I am unable to collect data from the detailed link.
The goal is to collect all the data from the detailed location page for each location on each list page.
What am I doing wrong?
Url: https://facilities.westkelownacity.ca/?CategoryIds=23&Page=[1-3]
Sitemap:
{"_id":"west_kelowna-playgrounds","startUrl":["https://facilities.westkelownacity.ca/?CategoryIds=23&Page=[1-3]"],"selectors":[{"id":"playground-links","type":"SelectorElementClick","parentSelectors":["playground-selector"],"selector":"h4","multiple":true,"delay":2000,"clickElementSelector":"h4","clickType":"clickMore","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["playground-links"],"selector":"h2","multiple":false,"regex":"","delay":0},{"id":"address","type":"SelectorText","parentSelectors":["playground-links"],"selector":".sidebar-feed p:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"hours","type":"SelectorText","parentSelectors":["playground-links"],"selector":".sidebar-feed li","multiple":false,"regex":"","delay":0},{"id":"description","type":"SelectorText","parentSelectors":["playground-links"],"selector":"p:nth-of-type(3)","multiple":false,"regex":"","delay":0},{"id":"photo","type":"SelectorImage","parentSelectors":["playground-links"],"selector":"img.photoItem","multiple":false,"delay":0},{"id":"playground-selector","type":"SelectorElement","parentSelectors":["_root"],"selector":"a.sidebar-item","multiple":true,"delay":0},{"id":"","type":"SelectorText","parentSelectors":["playground-links"],"selector":"","multiple":false,"regex":"","delay":0}]}