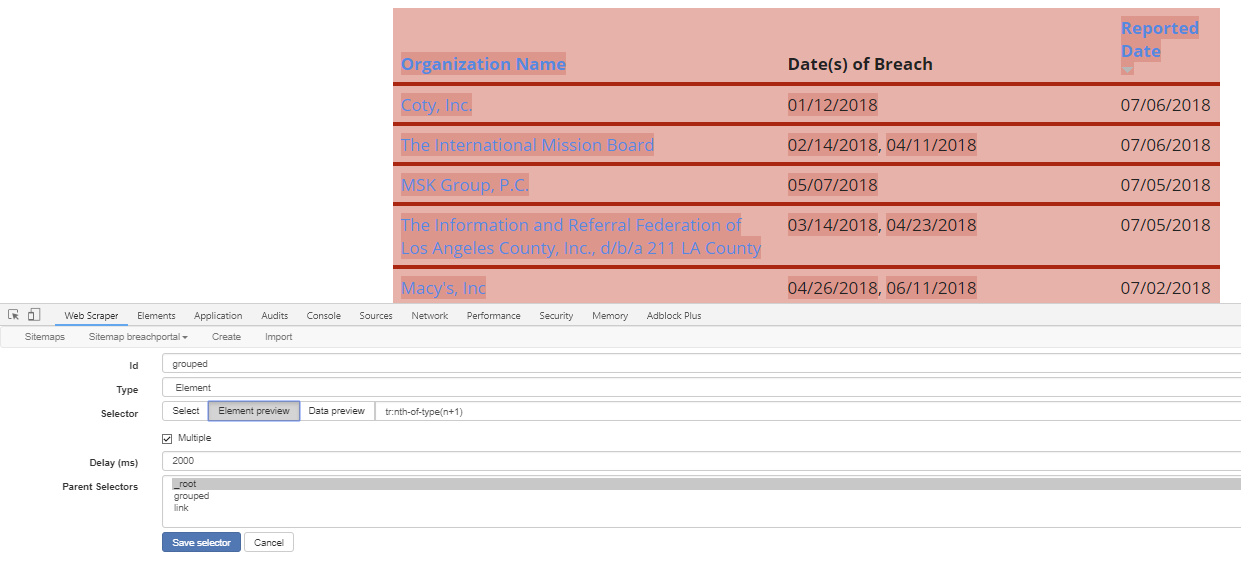
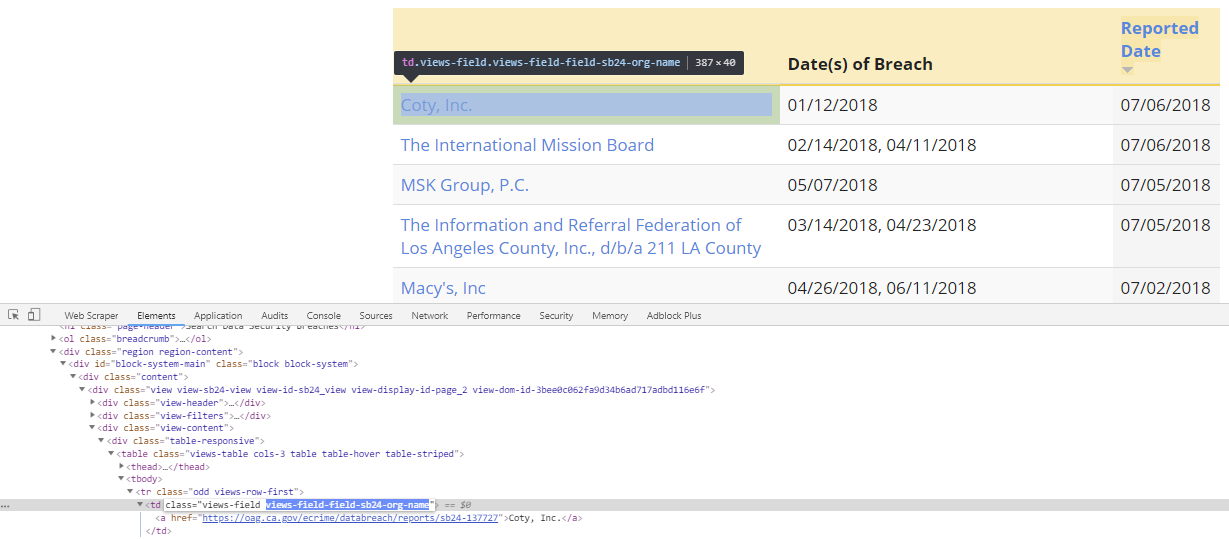
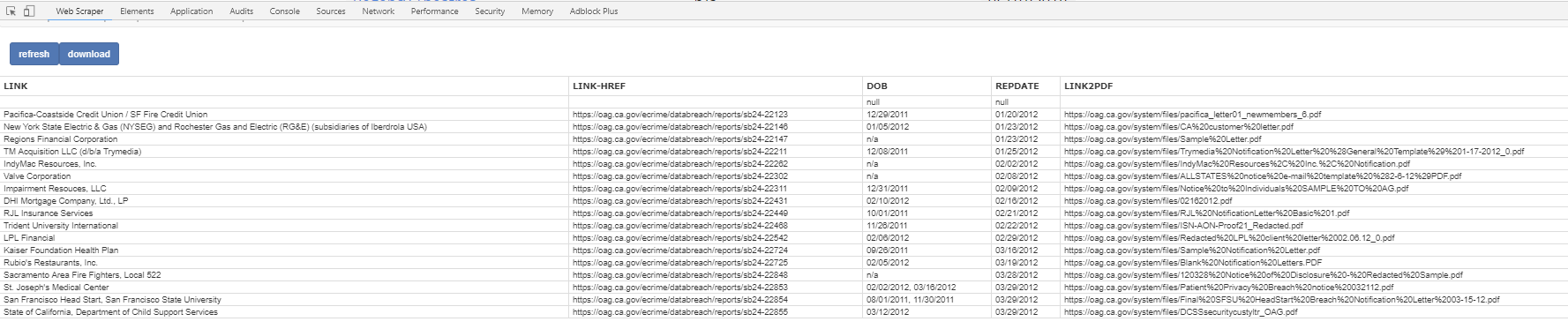
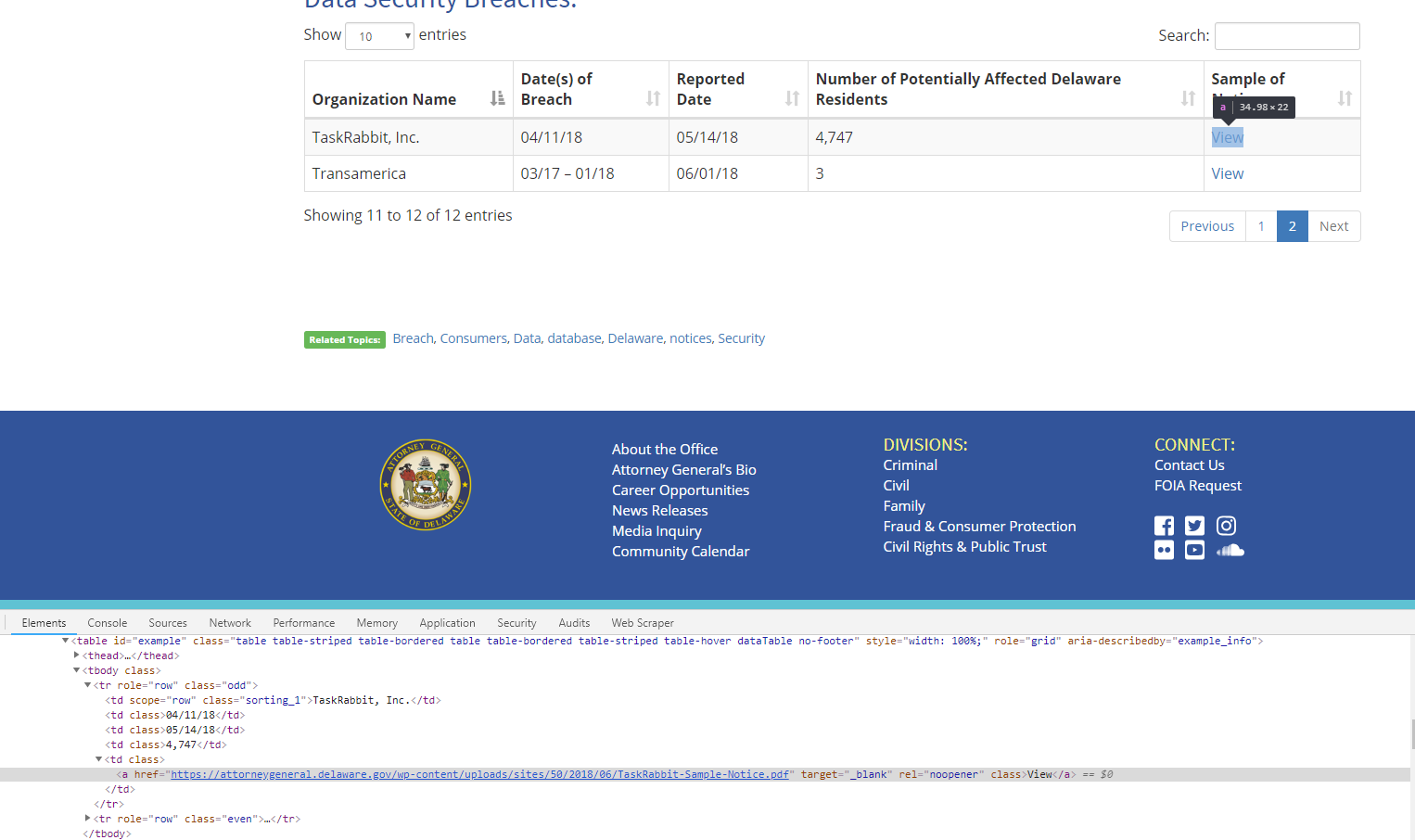
I'm trying to scrape from a table and include not only the text of the table but the link that each row contains. I've used "Table" element selector which gets very close, but doesn't pull the html link. I used "link" but while that pulls the link it doesn't put it on the same row as the scraped data from the table, which is ideal.
(Actually, if anyone can figure it out, what I'd really like to be able to do is to scrape the table data, then follow the link from each row, then include the link to the .pdf that is displayed on the linked page - if that makes sense; e.g.: the first row on https://oag.ca.gov/privacy/databreach/list is "California Department of Public Health", I'd like to scrape the name, the date the breach was made public, the date the breach occurred AND then get the actual link to the pdf that is included on the page that is linked to on each row, https://oag.ca.gov/system/files/Sample%20CDPH%20Breach%20Notification%20Letter_5_23_18_0.pdf )
I know no CSS or HTML, but I've had some success using the element selectors - is this something that the selectors can't do? Is there something I could be doing better? Thanks! Huge thanks for this program, it's helping us do some good work.
Url: https://oag.ca.gov/privacy/databreach/list
Sitemap:
{"_id":"ca-ag-breachportal","startUrl":["https://oag.ca.gov/privacy/databreach/list"],"selectors":[{"id":"tabledata","type":"SelectorTable","selector":"table.views-table","parentSelectors":["_root"],"multiple":true,"columns":[{"header":"Organization Name","name":"Organization Name","extract":true},{"header":"Date(s) of Breach","name":"Date(s) of Breach","extract":true},{"header":"Reported Date","name":"Reported Date","extract":true}],"delay":0,"tableDataRowSelector":"tbody tr","tableHeaderRowSelector":"thead tr"},{"id":"Link","type":"SelectorLink","selector":"td.views-field a","parentSelectors":["_root"],"multiple":true,"delay":0}]}