I would like to scrape a database of companies, getting three fields from each one of them.
I need to, first of all, click in a search button, then I have to enter in each of the company's detail page and here I would like to get those three text fields.
The urls are not dynamic....
Thanks for your advise
Url: http://www.impic.pt/impic/pt-pt/consultar/empresas-titulares-de-licenca-de-mediacao-imobiliaria
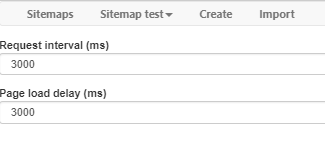
Sitemap:
{"_id":"impic","startUrl":["http://www.impic.pt/impic/pt-pt/consultar/empresas-titulares-de-licenca-de-mediacao-imobiliaria"],"selectors":[{"id":"next","type":"SelectorLink","parentSelectors":["start"],"selector":"div.col-sm-4.text-right a.btn","multiple":true,"delay":0},{"id":"element","type":"SelectorElementClick","parentSelectors":["next","start"],"selector":"div.block.impic-form","multiple":false,"delay":0,"clickElementSelector":"td.text-center:nth-of-type(3) a.btn-info","clickType":"clickOnce","discardInitialElements":false,"clickElementUniquenessType":"uniqueText"},{"id":"council","type":"SelectorText","parentSelectors":["element"],"selector":"div.information:nth-of-type(3) div.information-field:nth-of-type(3) span","multiple":false,"regex":"","delay":0},{"id":"district","type":"SelectorText","parentSelectors":["element"],"selector":"div.information:nth-of-type(3) div.information-field:nth-of-type(4) span","multiple":false,"regex":"","delay":0},{"id":"creation","type":"SelectorText","parentSelectors":["element"],"selector":"div.information:nth-of-type(3) div.information-field:nth-of-type(7) span","multiple":false,"regex":"","delay":0},{"id":"start","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"a.btn.btn-search","multiple":false,"delay":0,"clickElementSelector":"a.btn.btn-search","clickType":"clickOnce","discardInitialElements":false,"clickElementUniquenessType":"uniqueText"}]}