Hi.
im trying to scrape this link
https://www.linkedin.com/sales/search/company?companySize=D&geo=samerica%3A0%2Cbr%3A0%2Car%3A0%2Cco%3A0%2Cec%3A0%2Cpe%3A0%2Ccl%3A0%2Cpy%3A0%2Cuy%3A0%2Cbo%3A0%2Cve%3A0%2Cgy%3A0%2Csr%3A0&industry=3&page=2&searchSessionId=SAEt5TVHRL2vADSeLWDjBw%3D%3D
the first page is ok, then from the second page it will grab only the first 10 companies
it seems like starting from the 11th company, the rows are nested under another class called "deferred area"
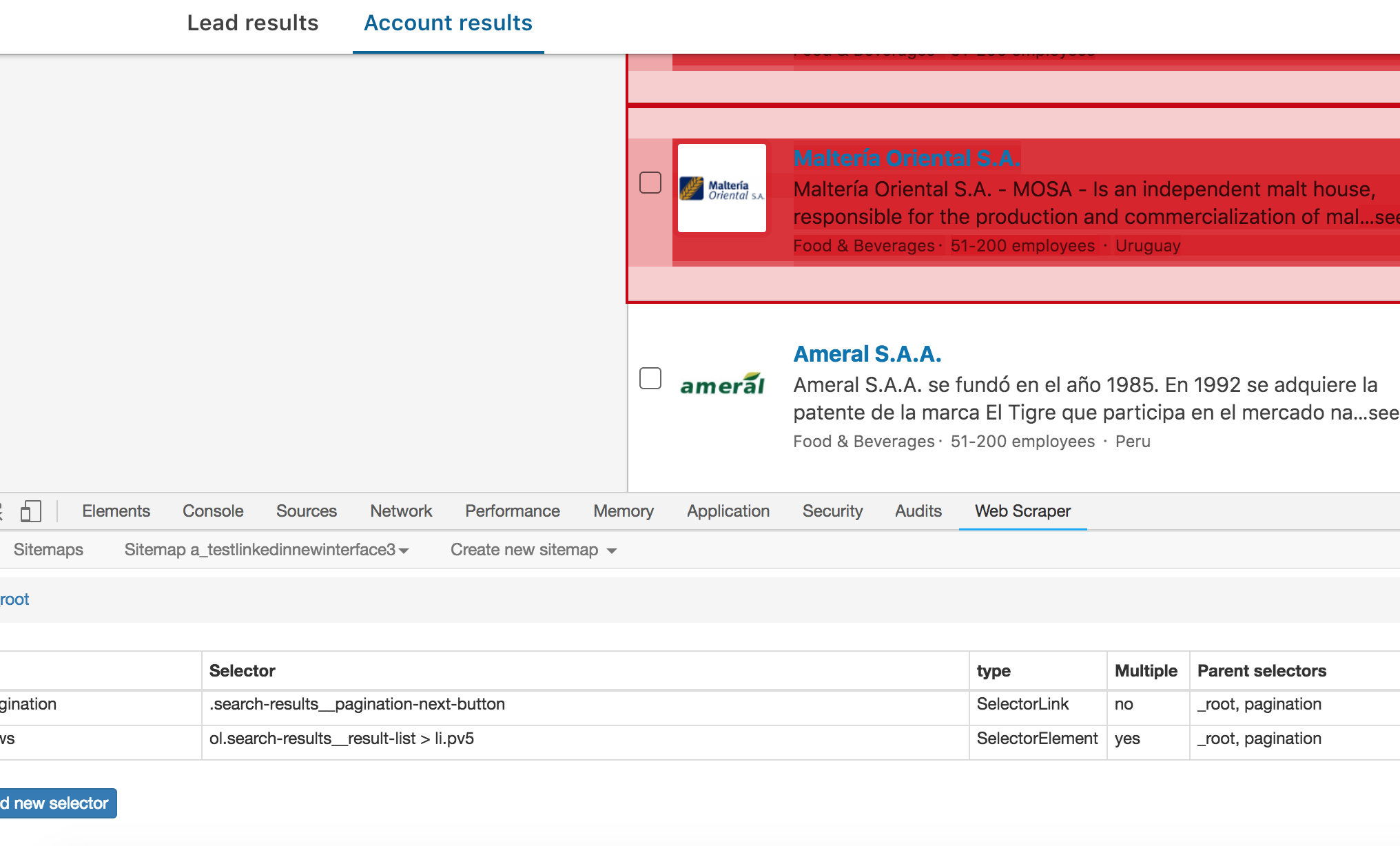
this is my sitemap
Sitemap:
{"_id":"selectall2","startUrl":["https://www.linkedin.com/sales/search/company?companySize=D&geo=samerica%3A0%2Cbr%3A0%2Car%3A0%2Ccl%3A0%2Cpe%3A0%2Cco%3A0%2Cve%3A0%2Cec%3A0%2Cuy%3A0%2Cbo%3A0%2Cpy%3A0%2Cgy%3A0%2Csr%3A0&industry=3&page=1&searchSessionId=SAEt5TVHRL2vADSeLWDjBw%3D%3D"],"selectors":[{"id":"pagination","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"li.pv5, div.deferred-area li.pv5","multiple":true,"delay":"2000","clickElementSelector":"button.search-results__pagination-next-button span.v-align-middle","clickType":"clickMore","discardInitialElements":false,"clickElementUniquenessType":"uniqueText"},{"id":"company","type":"SelectorText","parentSelectors":["pagination"],"selector":"dt.result-lockup__name a.ember-view","multiple":false,"regex":"","delay":"2000"}]}
how can i fix that?
thanks!