
Hey guys,
I’m looking for an regex that matches alle unicode letters. If I use for example [a-zA-Z]+ Then I’ve the problem that it won’t match with ëçZäöüßÄÖÜ.
Here’s an example of what I’m trying to do…. I’m scraping a website to fetch their image urls. An example is:
html = ……mobile-image=data-mobile-image="/media/3748/proefles-met-joël-delamar-theater.jpg?anchor=cente……….
Desired result : /media/3748/proefles-met-joël-delamar-theater.jpg
Regex that works for normal letters : media[a-zA-Z/0-9-._]+
Actual Result : media/3748/proefles-met-jo
Reason: it doesn't take the ë .
What do I need: regex that matches with Unicode letter category.
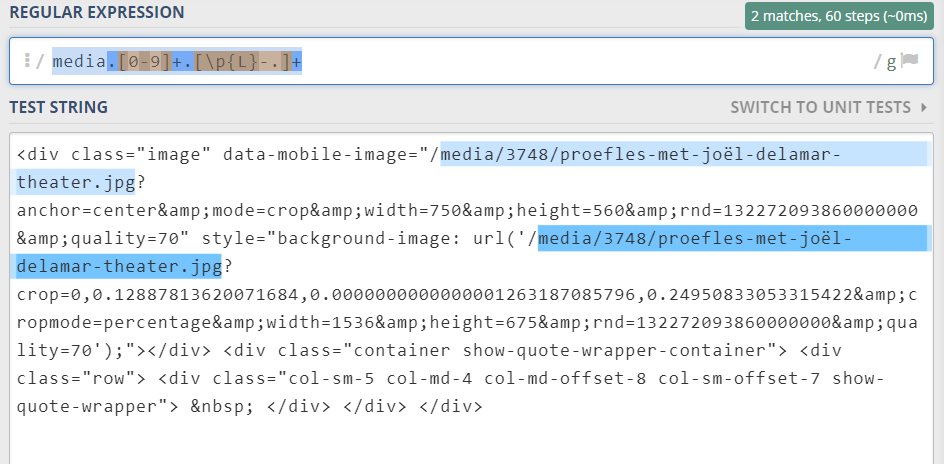
Therefore I used the folowing rexeg : media.[0-9]+.[\p{L}-.]+ OR media[/0-9\p{L}-.]+
- It seems like webscraper doesn't accept \p{L}
This one works when i try it in rexeg.com. See screenshot.
Do you how to make this work in webscraper. Or do you see what I’m doing wrong?
Url: https://delamar.nl/voorstellingen/joel-broekaert/
Sitemap:
{"_id":"delamar1","startUrl":["https://delamar.nl/voorstellingen/joel-broekaert/"],"selectors":[{"id":"foto","type":"SelectorHTML","parentSelectors":["root"],"selector":"div.details-header","multiple":false,"regex":"media[a-zA-Z/0-9-.]+","delay":0}]}