Hi all
ANYONE UP FOR A CHALENGE???
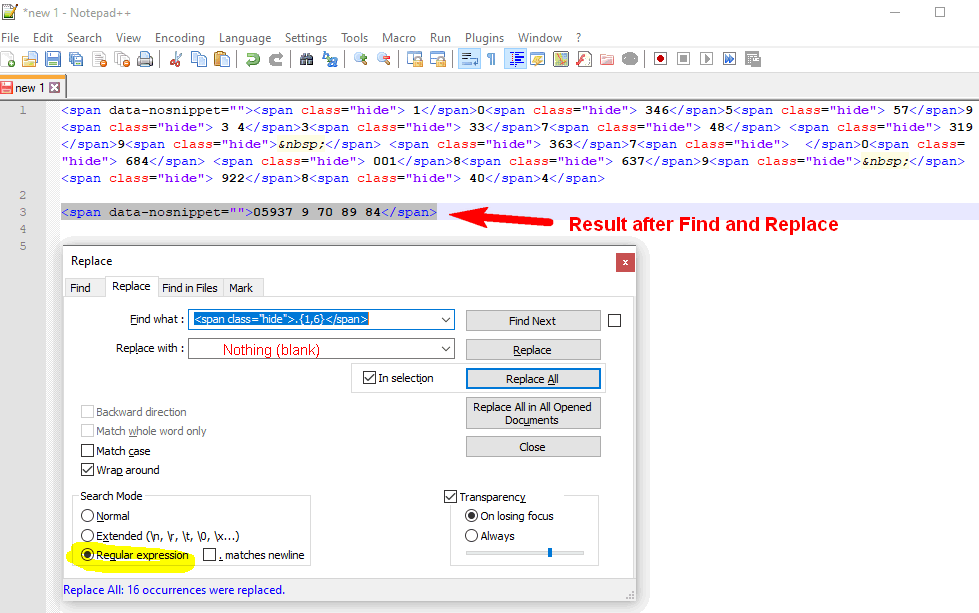
www.dastelefonbuch.de uses some new technology to make it hard for Web Scraper to get the correct data. They use random hidden tags on the data values to manipulate phone numbers etc.
Here is a example result that I like to scrape:
But I get wrong values.
Can anyone help with such example?
Thanks
Martin