So what you want to do is goto https://sqlify.io/convert/json/to/csv and click "Input a URL", paste https://api.troostwijkauctions.com/lot/7/list?batchSize=999&listType=7&offset=0&sortOption=0&saleID=27213&parentID=0&relationID=0&buildversion=201807311 & click CSV & then Convert to CSV
That page contains all the information you wanted, title of the auction + all the data for each item (displayed on the items page)
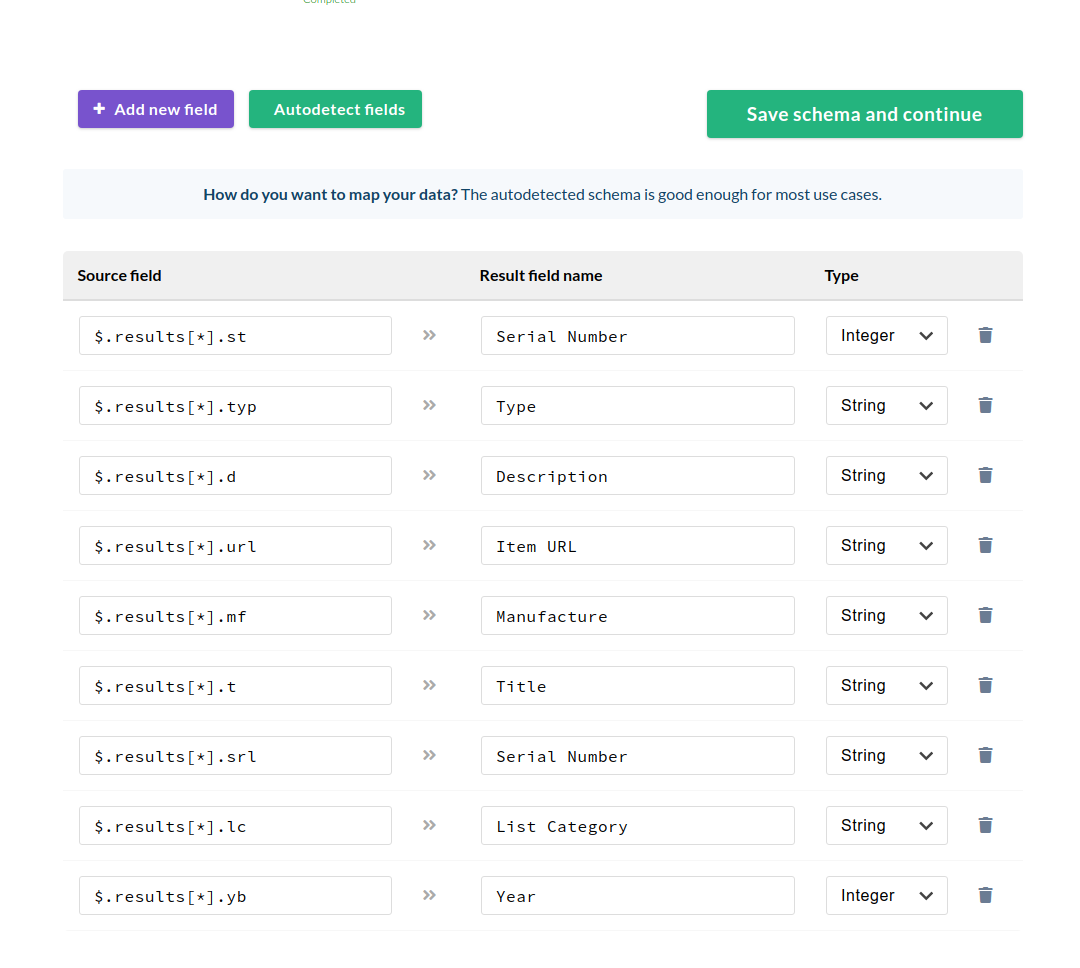
After you click Convert to CSV, it will take you to a page to map the extracted data
It will have 3 columns, Source field, Result field name, Type
Do not touch Source field.
Result field name are column names, so you can edit those to what you want in the final CSV.
Go ahead and click the trashcan icon next to the lines you do not need/want
$.results[].t = Title of the post
$.results[].lc = List Category
$.results[].d = Item Description (under post title on the listing page)
$.results[].mf = Manufacture
$.results[]..srl = Serial Number of device
$.results[].typ = Type
$.results[].yb = Year
$.results[].url = url to detail page (minus https://www.troostwijkauctions.com/nl/)
After you are done click Save schema and continue
Download the CSV
To resolve the urls of the items, just prepend https://www.troostwijkauctions.com/nl/ to them all
Might be easiest to copy the json into notepad++ and use find/replace
Find: "url": "
Replace: "url": "https://www.troostwijkauctions.com/nl
Then copy that and convert it to CSV