The scraper is going through the pages all fine but somehow only the last page's content shows up in the data (I get one row of output).
Url: http://principlesofaccounting.com/chapter-1/
Sitemap:
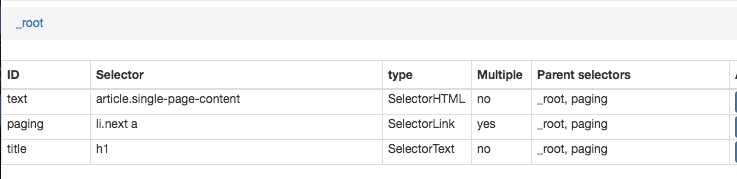
{"_id":"principlesofaccounting","startUrl":["https://www.principlesofaccounting.com/chapter-1/"],"selectors":[{"id":"text","type":"SelectorHTML","selector":"article.single-page-content","parentSelectors":["_root","paging"],"multiple":false,"regex":"","delay":0},{"id":"paging","type":"SelectorLink","selector":"li.next a","parentSelectors":["_root","paging"],"multiple":false,"delay":0},{"id":"title","type":"SelectorText","selector":"h1","parentSelectors":["_root","paging"],"multiple":false,"regex":"","delay":0}]}
Alternatively, this startUrl can be used (so it will only go through the last two pages): https://www.principlesofaccounting.com/chapter-24/compound-interest/