
Describe the problem.
I have set up a sitemap that scrapes information from a school sports program website. Currently the sitemap works as follows:
select school link > select respective sport page link > scrape sport information; select coach contact information link > scrape coaches email.
The problem lies on sport pages where a coach contact information link is not present, usually due to the sports program being discontinued. when this happens web scraper will get stuck on a coach less page and proceed to cycle through the rest of the sports listed without scraping anything.
I then end up with data that looks like this:
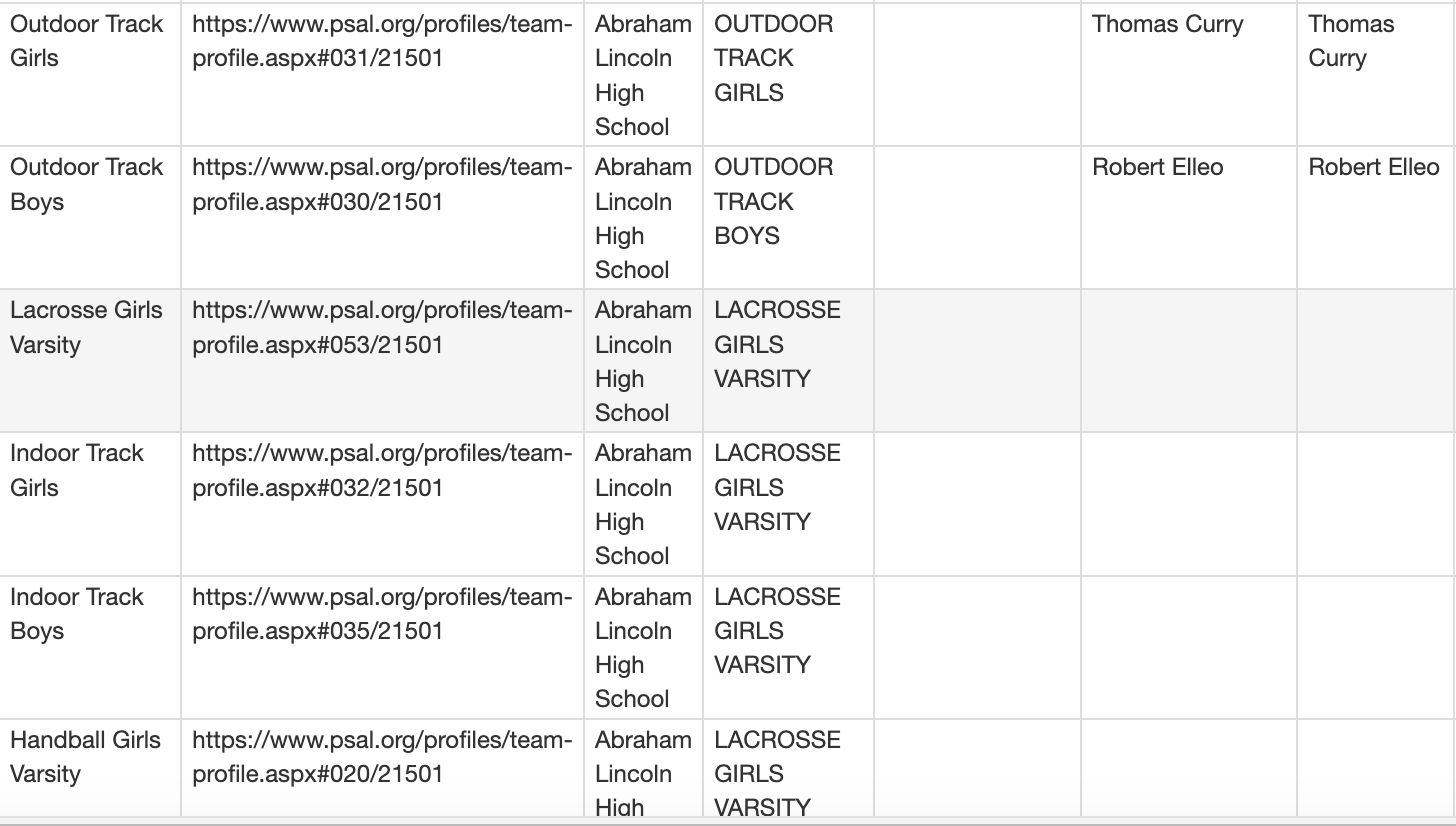
This is a sample site map for just the school abraham lincoln as this is one of the school pages with the above scraping problem
Sitemap:
{"_id":"Coach_test","startUrl":["https://www.psal.org/"],"selectors":[{"id":"Abraham lincoln","linkType":"linkFromHref","multiple":false,"parentSelectors":["_root"],"selector":"li.ss:nth-of-type(3) a","type":"SelectorLink"},{"id":"lincoln_sports","linkType":"linkFromHref","multiple":true,"parentSelectors":["Abraham lincoln"],"selector":"tr:nth-of-type(n+2) td:nth-of-type(1) a","type":"SelectorLink"},{"id":"School","multiple":false,"parentSelectors":["lincoln_sports"],"regex":"","selector":"span#schoolName","type":"SelectorText"},{"id":"Sport","multiple":false,"parentSelectors":["lincoln_sports"],"regex":"","selector":"span#fullSpName","type":"SelectorText"},{"id":"Division","multiple":false,"parentSelectors":["lincoln_sports"],"regex":"","selector":"span#location","type":"SelectorText"},{"id":"Coach_FullName","multiple":false,"parentSelectors":["lincoln_sports"],"regex":"","selector":"#headCoach a","type":"SelectorText"},{"id":"Coach_Link","linkType":"linkFromHref","multiple":false,"parentSelectors":["lincoln_sports"],"selector":"#headCoach a","type":"SelectorLink"},{"id":"Email","multiple":false,"parentSelectors":["Coach_Link"],"regex":"","selector":"a#coachEmail","type":"SelectorText"}]}