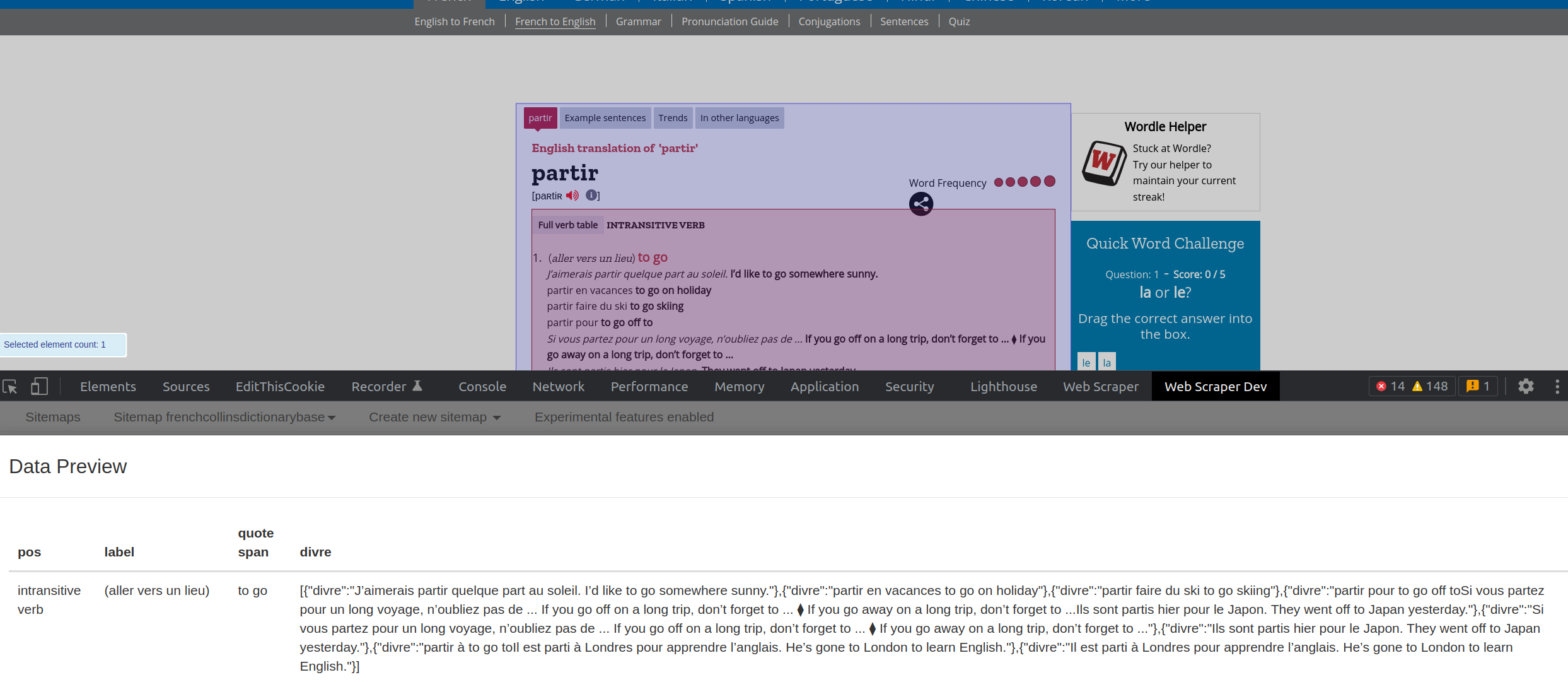
I am trying to scrape from a French dictionary site to make flashcards, and in order to make my life a whole lot easier, I cannot, for the life of me, figure out how to format the data properly.
Here's what I mean:
Current Progress:
Title | Phonetic | POS | Label | Quote Span | Form | Quote
Title | Phonetic | POS | Label | Quote Span | Form | Another Quote
Title | Phonetic | POS | Label | Quote Span | Another Form | Quote
Title | Phonetic | POS | Label | Quote Span | Another Form | Another Quote
Aim:
Title | Phonetic | POS | Label | Quote Span | Form | Quote | POS | Label Quote Span | Form | Quote etc. etc. with all of the data for one word on one line.
Here's an explanation of the selectors:
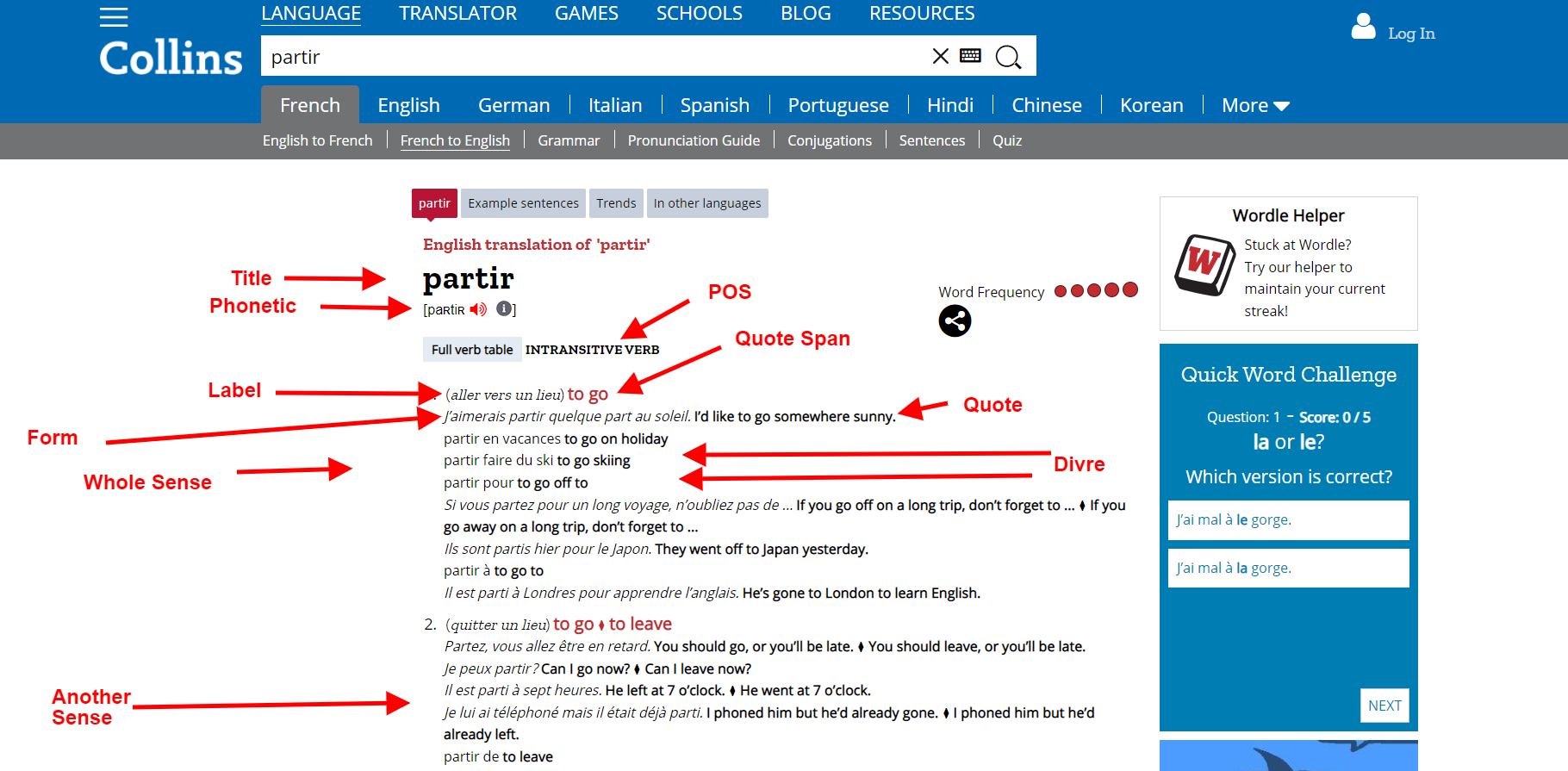
URL: https://www.collinsdictionary.com/dictionary/french-english/partir (just an example)
Sitemap:
{"_id":"frenchcollinsdictionarybase","startUrl":["https://pastelink.net/z8mt2ijb"],"selectors":[{"id":"dictionary","parentSelectors":["links"],"type":"SelectorElement","selector":"div.dc","multiple":true,"delay":0},{"id":"title","parentSelectors":["dictionary"],"type":"SelectorText","selector":".h2_entry span","multiple":false,"delay":0,"regex":""},{"id":"phonetic","parentSelectors":["dictionary"],"type":"SelectorText","selector":".form span.pron","multiple":false,"delay":0,"regex":""},{"id":"hom","parentSelectors":["dictionary"],"type":"SelectorElement","selector":"div.hom","multiple":true,"delay":0},{"id":"pos","parentSelectors":["hom"],"type":"SelectorText","selector":"span.pos","multiple":false,"delay":0,"regex":""},{"id":"sense","parentSelectors":["hom"],"type":"SelectorElement","selector":"div.sense","multiple":true,"delay":0},{"id":"label","parentSelectors":["sense"],"type":"SelectorText","selector":"> span.gramGrp, span.lbl","multiple":false,"delay":0,"regex":""},{"id":"quote span","parentSelectors":["sense"],"type":"SelectorText","selector":"> span span.quote","multiple":false,"delay":0,"regex":""},{"id":"divre","parentSelectors":["sense"],"type":"SelectorElement","selector":"div.re","multiple":true,"delay":0},{"id":"form","parentSelectors":["divre"],"type":"SelectorText","selector":"span.form","multiple":false,"delay":0,"regex":""},{"id":"quote","parentSelectors":["divre"],"type":"SelectorText","selector":"span.quote","multiple":false,"delay":0,"regex":""},{"id":"links","parentSelectors":["_root"],"type":"SelectorLink","selector":".body-display a","multiple":true,"delay":0}]}