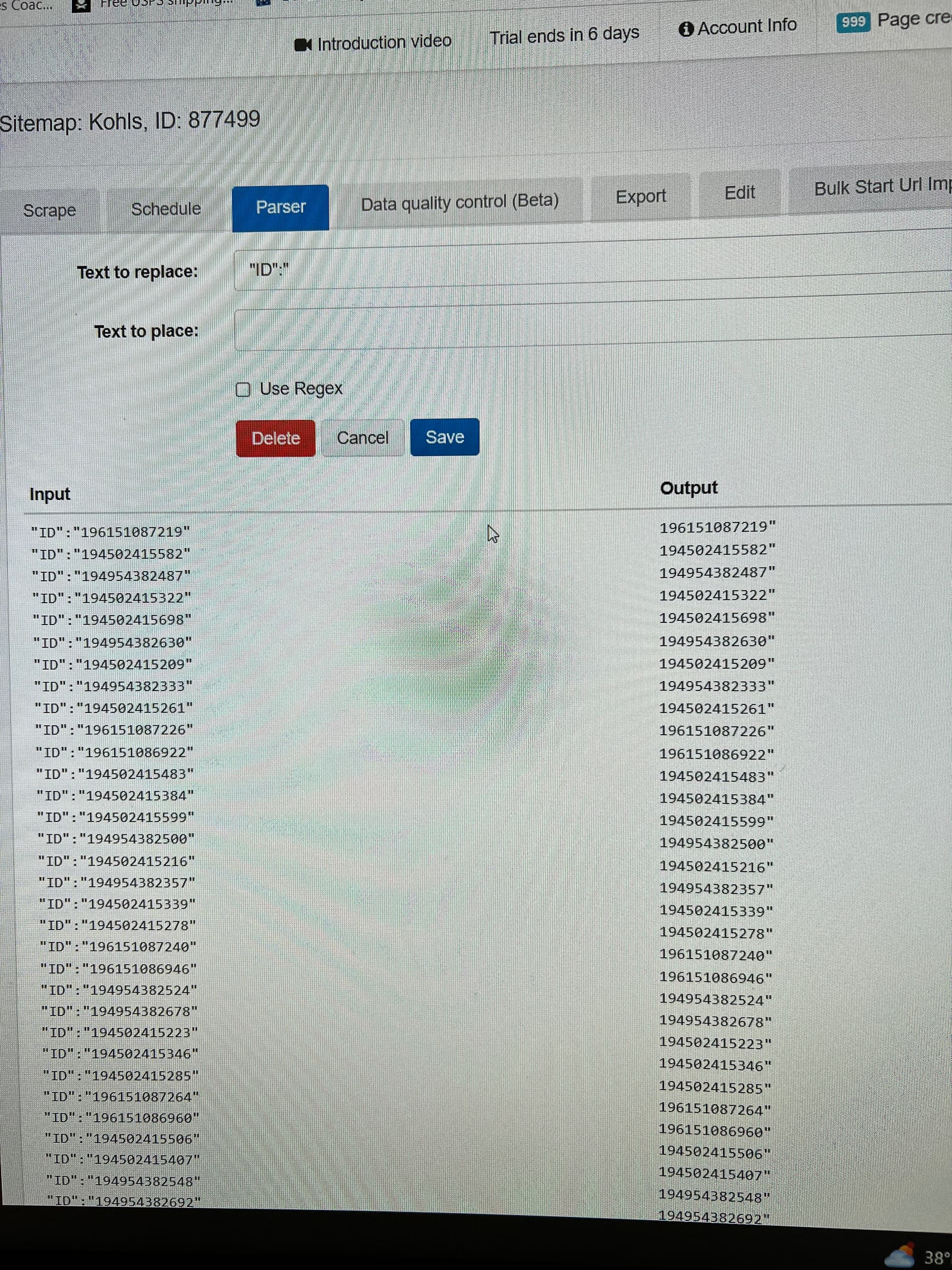
Hi, I was looking to scrape the numbers after the highlights part that I found in the source code and can’t seem to figure out how to do it.
@Quins Hi, could you, please, provide the targeted website?
In most cases such data is embedded within a script, therefore you can use a selector like: script:contains("ID") with a regex -"ID.*":"
Hi, here is a different product but the same concept applies
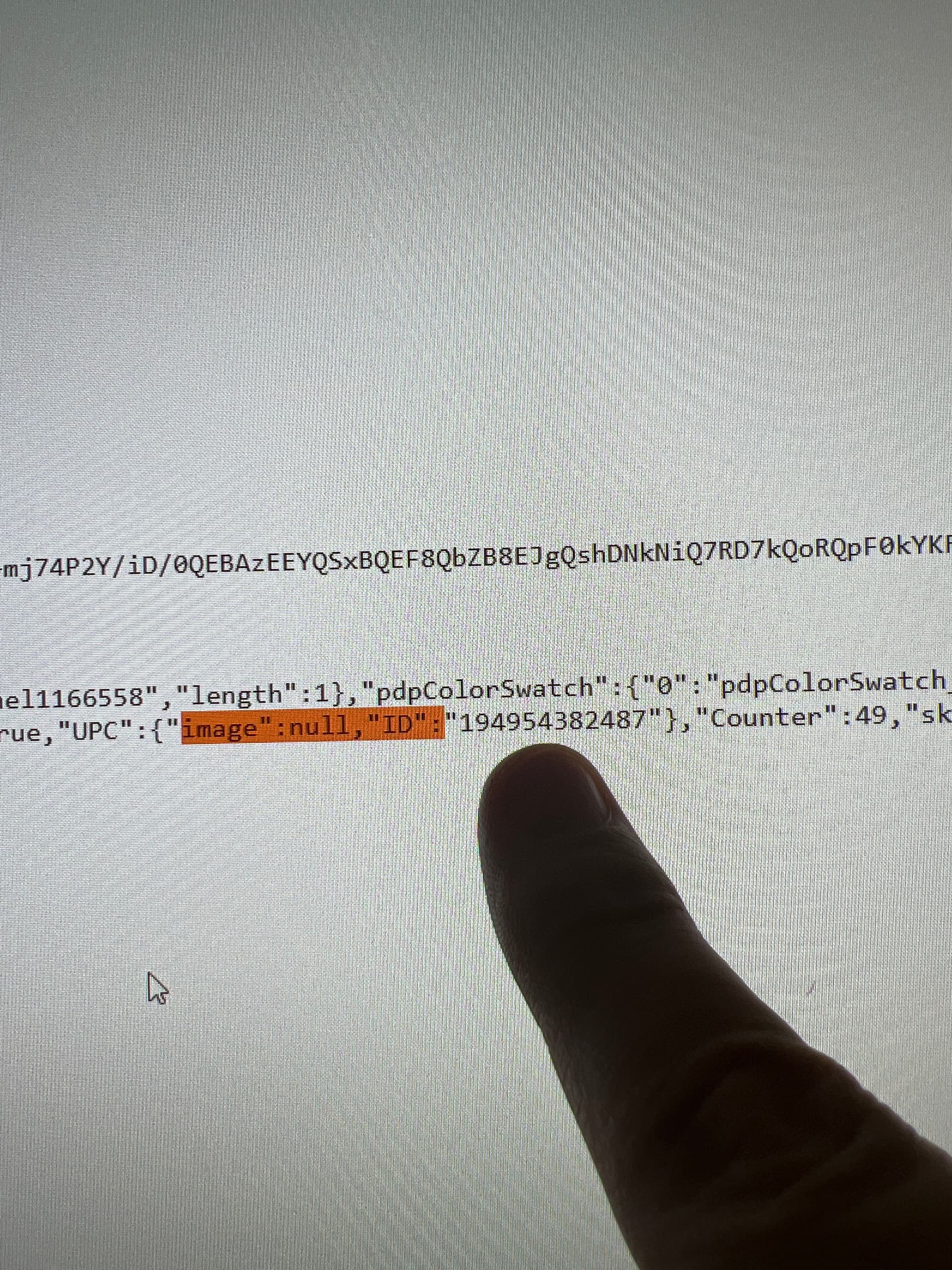
@Quins Hi, it is possible to extract this data by using the following selector script[type="text/javascript"]:contains("ID") ; regex": "ID".*
However, additional data post-processing will be required in order to isolate this data from the rest of the script text using the parser feature within cloud scraper. See the screenshot. Learn more: Parser | Web Scraper Documentation
Sitemap:
{"_id":"kohls-variation-test-2","startUrl":["https://www.kohls.com/product/prd-3818637/mens-nike-sportswear-club-tee.jsp?prdPV=27"],"selectors":[{"id":"ID-script","multiple":false,"parentSelectors":["_root"],"regex":"\"ID\".*","selector":"script[type=\"text/javascript\"]:contains(\"ID\")","type":"SelectorText"}]}
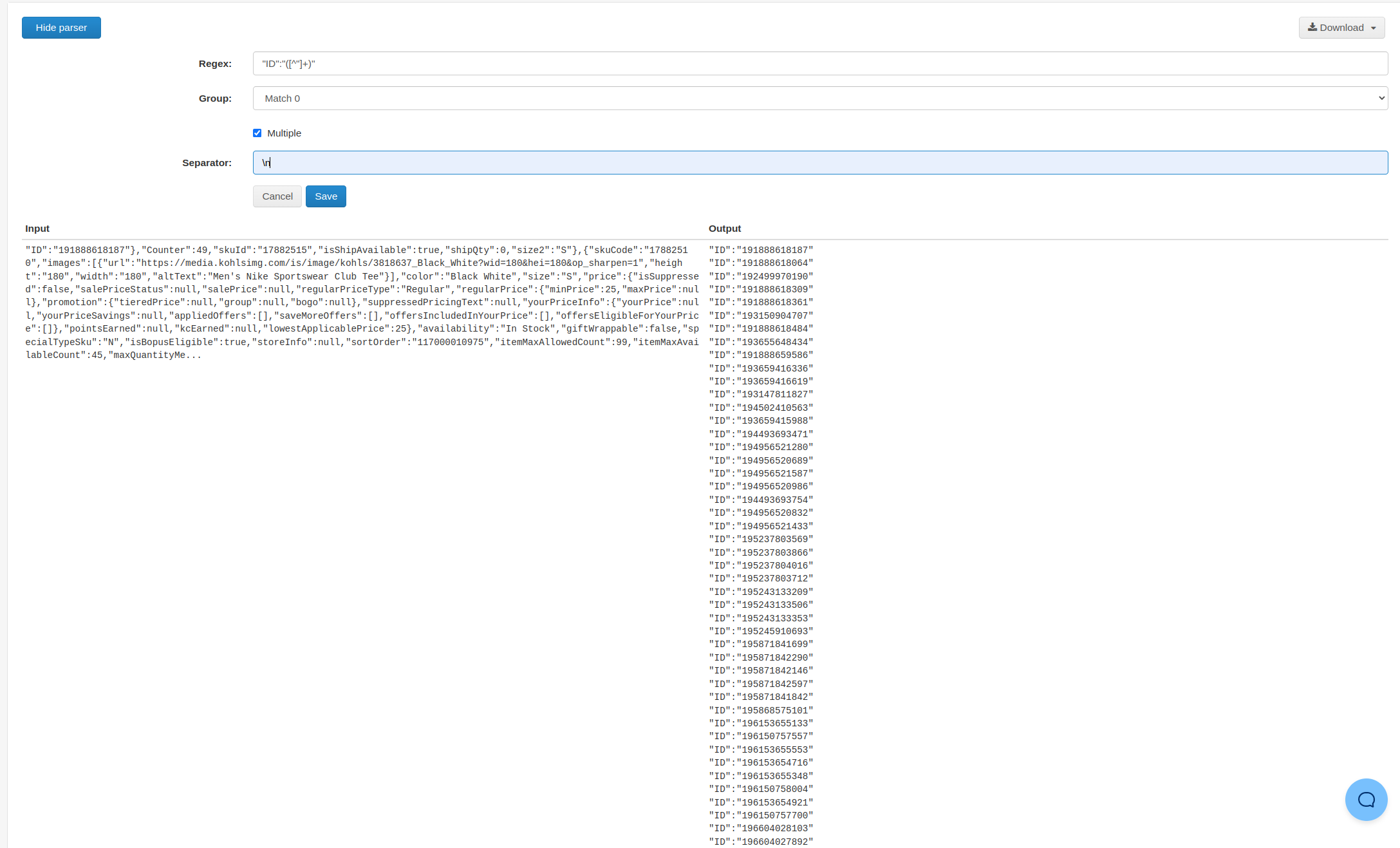
Oh my gosh. Thank you so much!! I was able to get almost everything removed besides that last “ any tips?