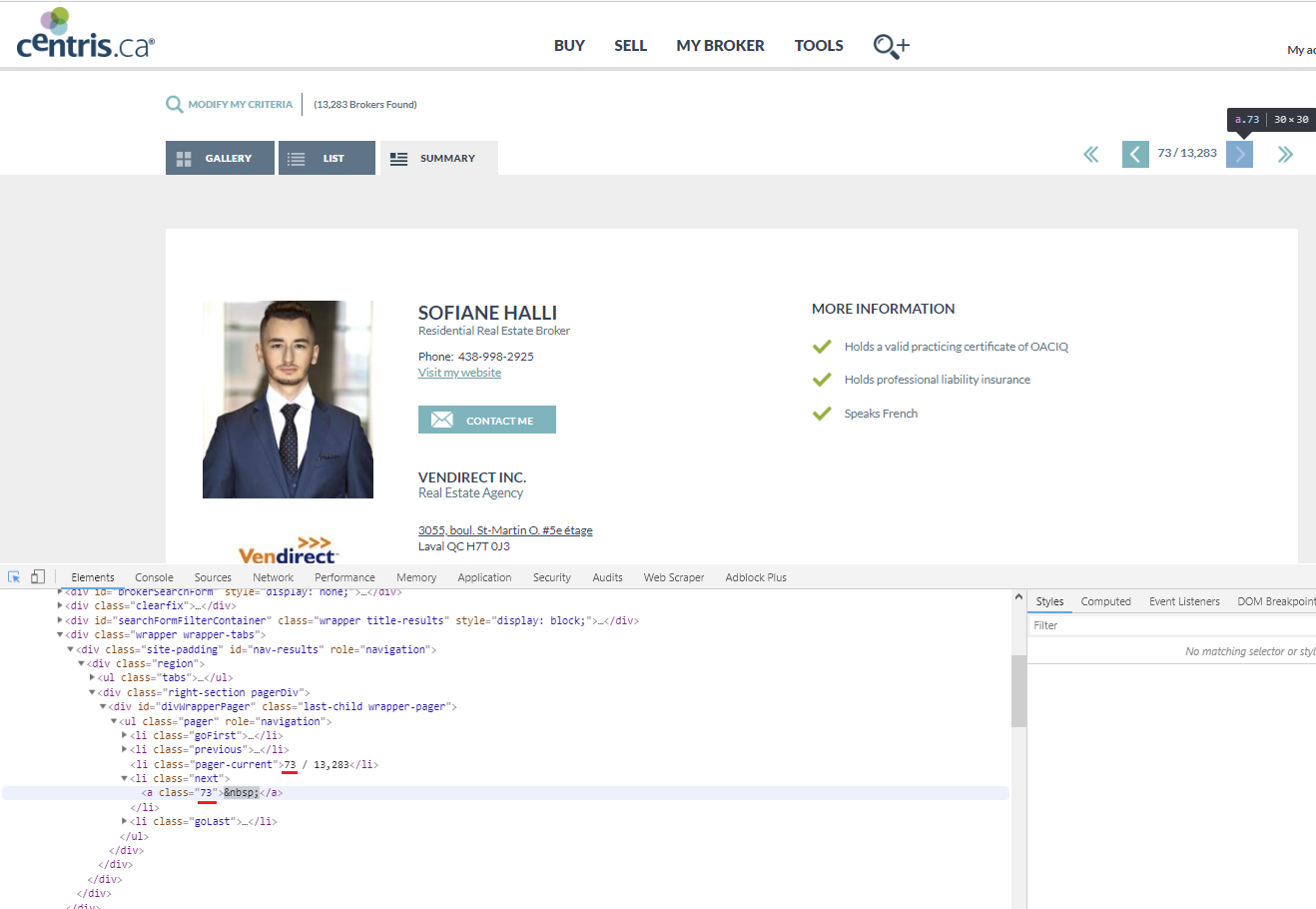
In this website, i try to extract all the contacts with postal informations for my project and can't get working the pagination because the a button are called has "blank" &nbps; and only the first page are getting data collected.
i try with LINK and also Element Link without working. It's stop on first page and not loading the page.
I need help please.
Any help is appreciated. Also, if you send me the corrected sitemap, tell me how you resolved it. I want to know how to resolve this issue on another project.
Thanks a lot.
sitemap:
{"_id":"centris","startUrl":["https://www.centris.ca/fr"],"selectors":[{"id":"mon courtier","type":"SelectorLink","parentSelectors":["_root"],"selector":"li:nth-of-type(3) a.main-item","multiple":false,"delay":0},{"id":"trouver un courtier","type":"SelectorLink","parentSelectors":["mon courtier"],"selector":"h2.nav-title.first a","multiple":false,"delay":0},{"id":"sommaire","type":"SelectorLink","parentSelectors":["trouver un courtier"],"selector":"li.summary a.current","multiple":false,"delay":0},{"id":"nom de l'agent","type":"SelectorText","parentSelectors":["sommaire","pagination"],"selector":"h1.name span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"nom de l'agence","type":"SelectorText","parentSelectors":["sommaire","pagination"],"selector":"div.agencyid h2.smaller","multiple":false,"regex":"","delay":0},{"id":"adresse","type":"SelectorText","parentSelectors":["sommaire","pagination"],"selector":"span.address a span","multiple":false,"regex":"","delay":0},{"id":"ville, province, code","type":"SelectorText","parentSelectors":["sommaire","pagination"],"selector":"p.agencycontact span.address > span","multiple":false,"regex":"","delay":0},{"id":"telephone","type":"SelectorText","parentSelectors":["sommaire","pagination"],"selector":"p.agencycontact span.phone span","multiple":false,"regex":"","delay":0},{"id":"pagination","type":"SelectorElementClick","parentSelectors":["_root","sommaire","pagination"],"selector":"div.right-section li.next a","multiple":false,"delay":0,"clickElementSelector":"div.right-section li.next a","clickType":"clickOnce","discardInitialElements":false,"clickElementUniquenessType":"uniqueText"}]}