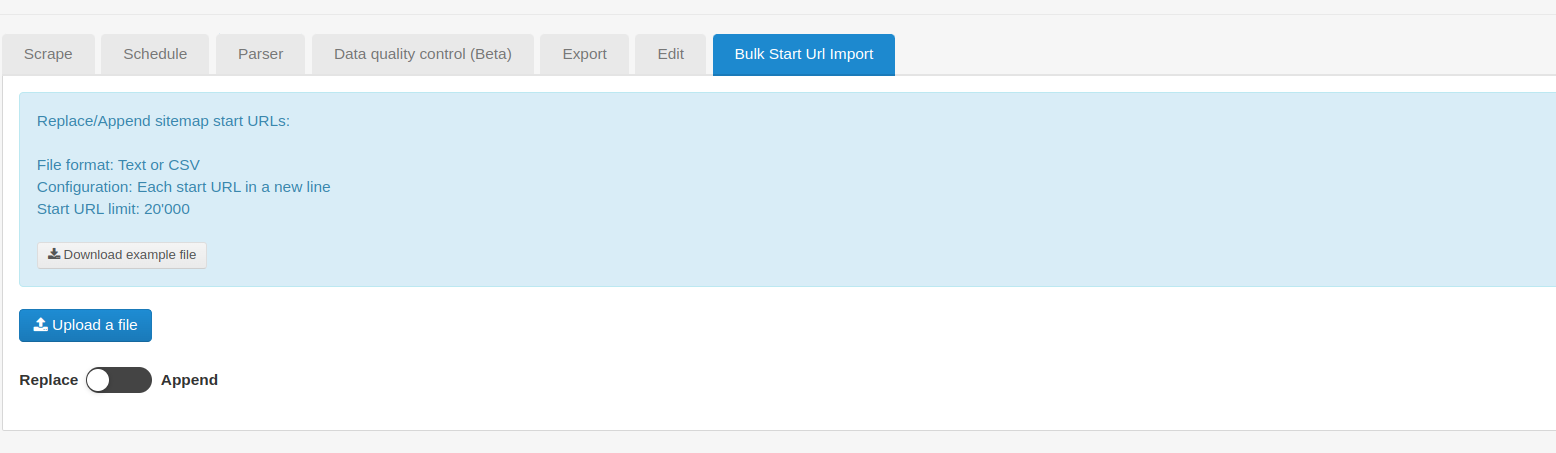
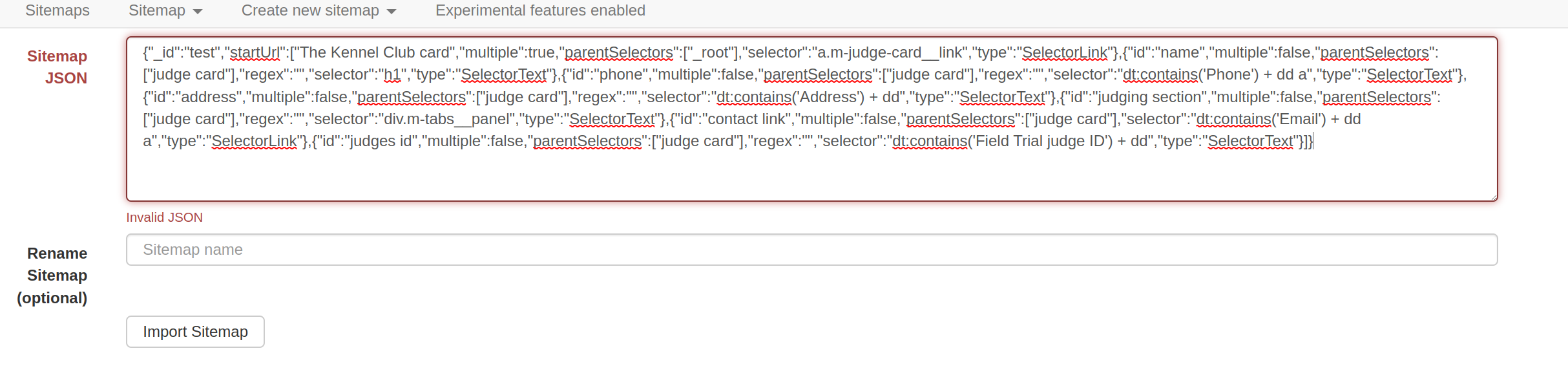
How does this work? I have defined two Start URL links in the site map meta data. I save this and get presented at the _root with the option to 'Add new selector'
How are the multiple start URL's iterated. In my situation the multiple start URL's are actually the links to a returned page from different search criteria. I require the same scrap from each.
At present when I try to save the results I'm only getting the data from one of the Start URL's