
Hello,
I would like to scrape data from CueTracker - 2023 World Championship - Snooker Results & Statistics
Each match is in its own div .match
I have tried this Sitemap:
{"_id":"snooker_worldchampionship_2023","startUrl":["https://cuetracker.net/tournaments/world-championship/2023/5550"],"selectors":[{"id":"game_title","multiple":true,"parentSelectors":["match div"],"regex":"","selector":"h5","type":"SelectorText"},{"id":"player_1","multiple":true,"parentSelectors":["match div"],"regex":"","selector":".player_1_name a","type":"SelectorText"},{"id":"player_2","multiple":true,"parentSelectors":["match div"],"regex":"","selector":".player_2_name a","type":"SelectorText"},{"id":"match div","multiple":true,"parentSelectors":["_root"],"selector":".match","type":"SelectorElement"}]}
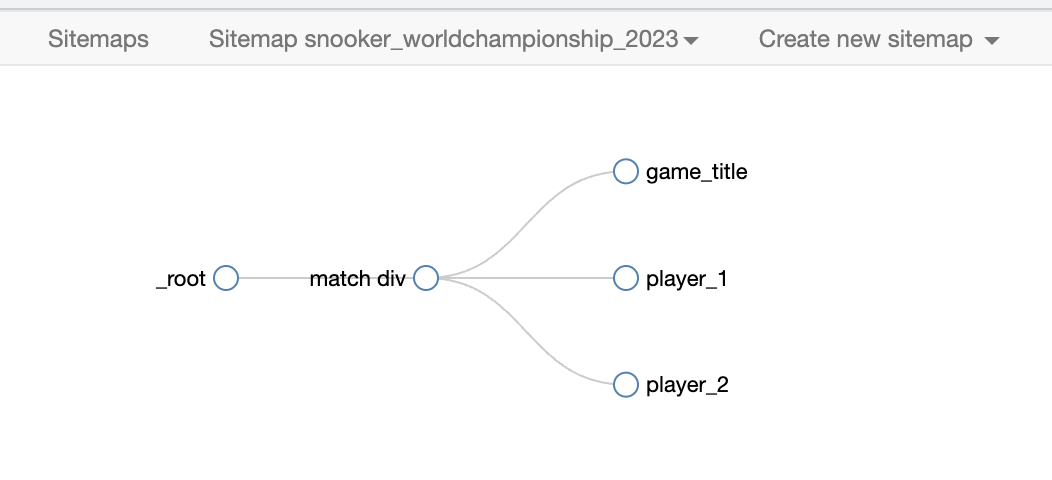
But it creates a row for each selector and does not have 1 row per match with all 3 selectors in this row.

I've also tried to include every div between parent element and text I want to extract, but it didn't change the data.
{"_id":"snooker_worldchampionship_2023","startUrl":["https://cuetracker.net/tournaments/world-championship/2023/5550"],"selectors":[{"id":"game_title","multiple":true,"parentSelectors":["match div"],"regex":"","selector":".col-md-12 .row .round_name h5","type":"SelectorText"},{"id":"player_1","multiple":true,"parentSelectors":["match div"],"regex":"","selector":".col-md-12 .row .player_1_name b a","type":"SelectorText"},{"id":"player_2","multiple":true,"parentSelectors":["match div"],"regex":"","selector":".col-md-12 .row .player_2_name a","type":"SelectorText"},{"id":"match div","multiple":true,"parentSelectors":["_root"],"selector":".match","type":"SelectorElement"}]}
And according to the sitemap on this page: Web Scraper << How to >> Scrape multiple items within a listings page this should not be necessary.
What am I missing.
Thanks,
Irene
PS: Using Chrome Version 112.0.5615.137 with the free extension