Hello @bh4ru.
Without seeing the actual sitemap I would still recommend using the "Grouped" selector.
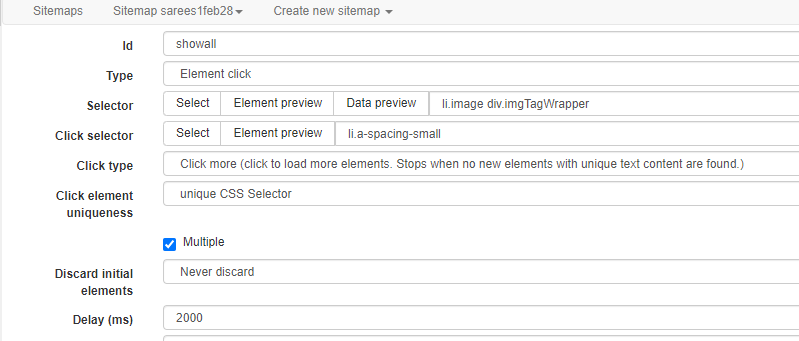
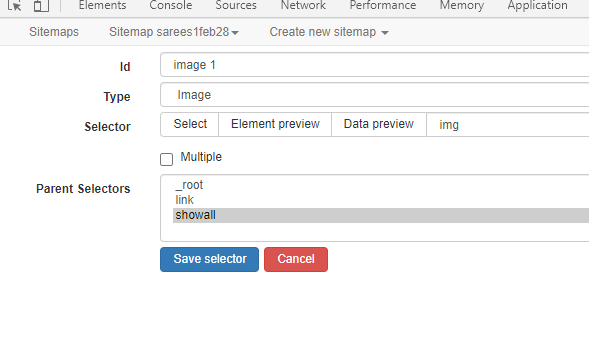
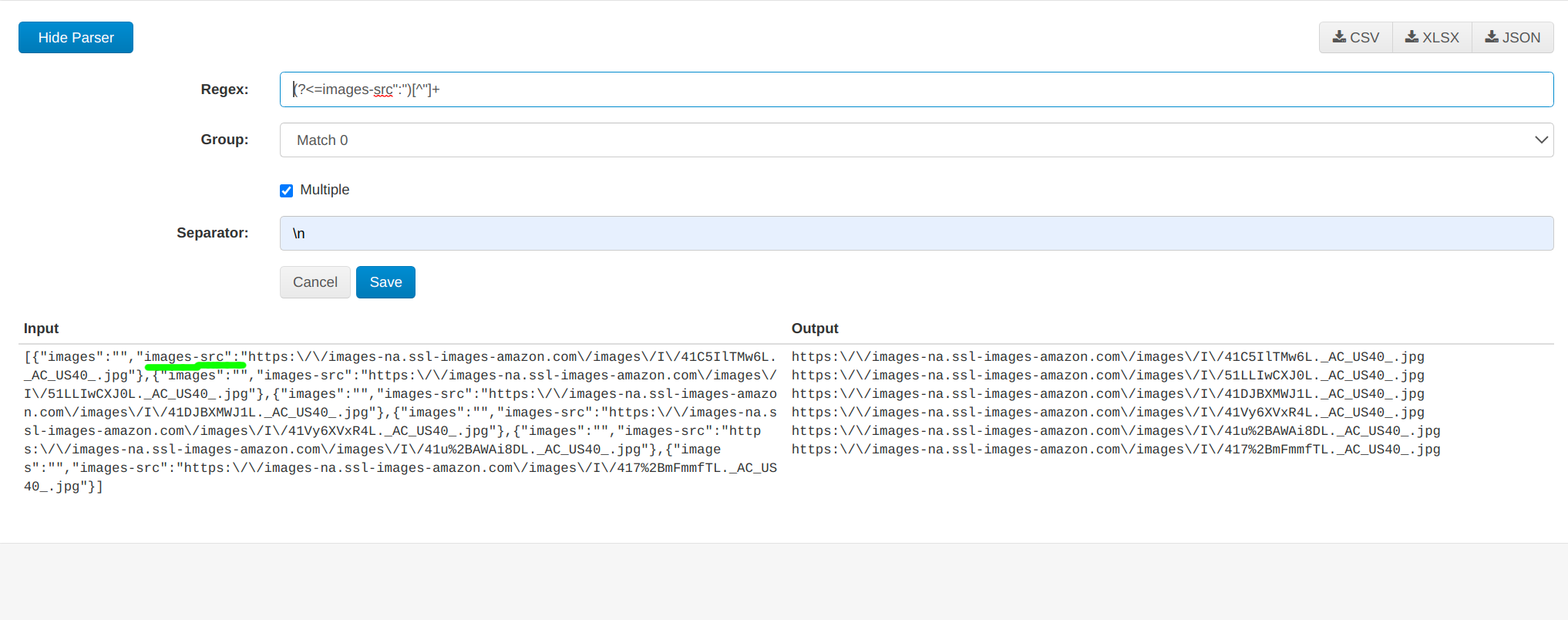
My set-up for image extraction looks like this:
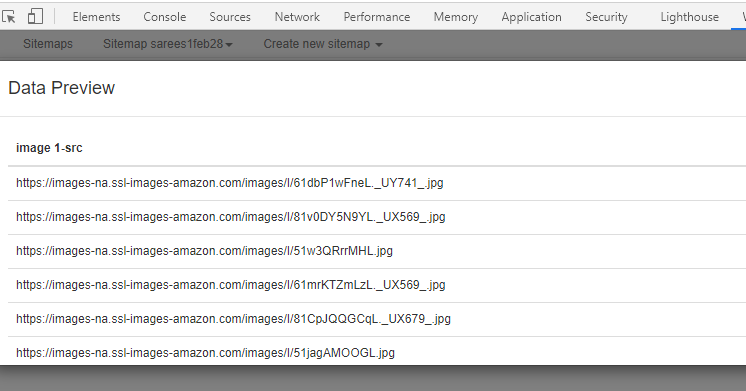
At data preview the extracted information looks like this:
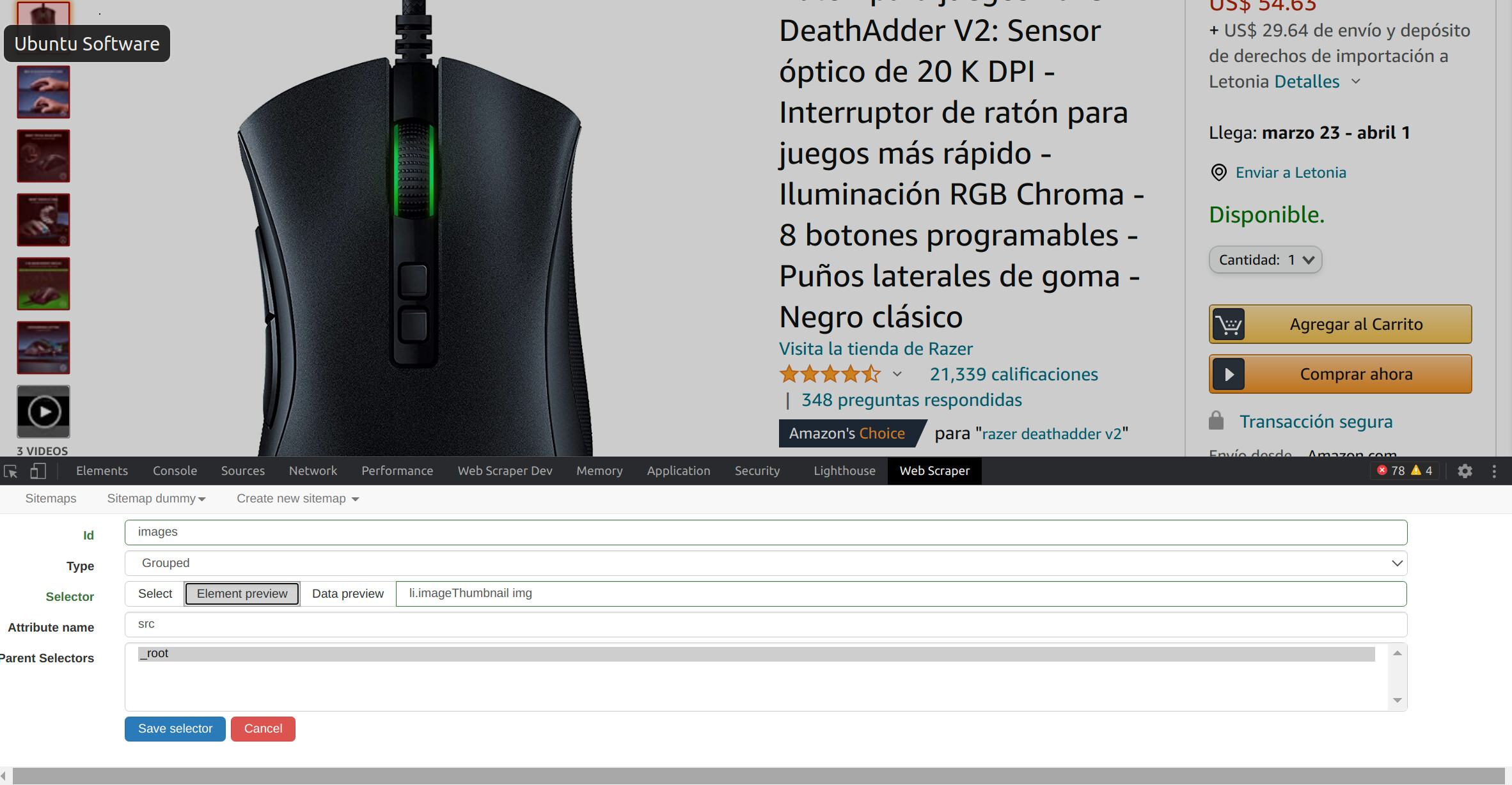
When I copy the image link i see that it's a bit too small:
But i notice a pattern between the large one and the small one:
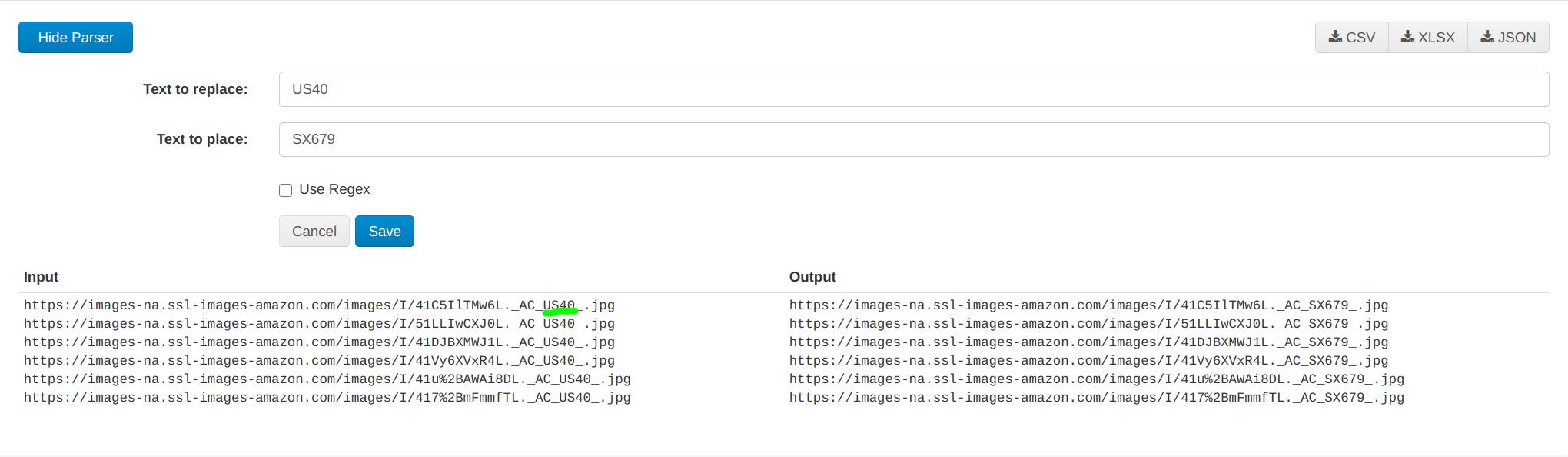
So basically after all of the data is scraped our mission is to clean up the data using regex and text-replace the part containing "US40" to "SX679" which are available in Web Scraper Cloud using a parser.
Steps which I perform in parser to get the desired data.
Regex match to get rid of redundant words
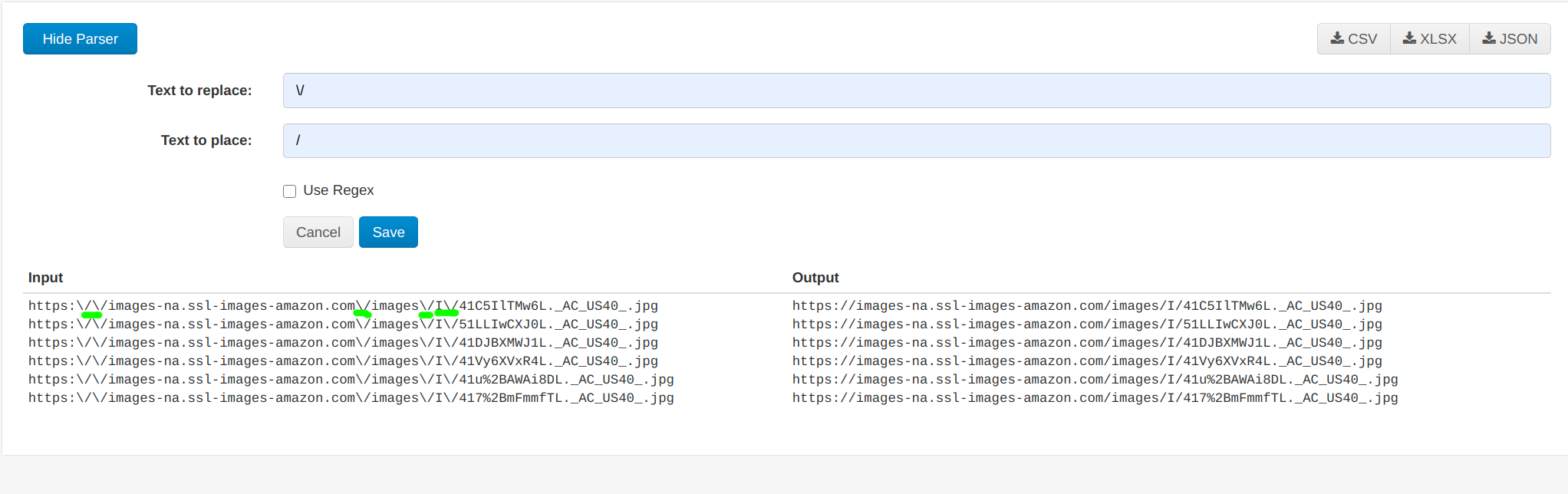
Slash Adjustment using - Replace Text
Word substitution - Replace Text
Hope it helps!