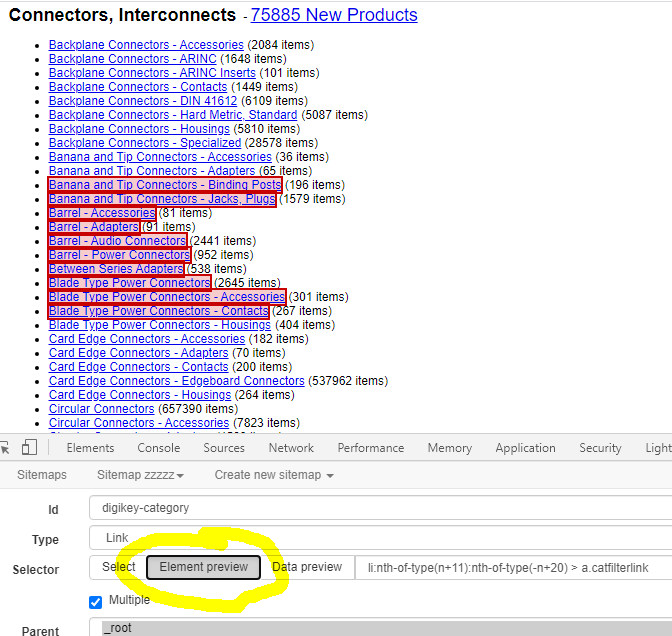
Hello, can I restrict by criteria - for example the first symbol the links I visit? The information I collect is a lot and at some point the resources on my computer are exhausted, so I want to divide the task into several smaller ones. When I work in another section with fewer categories, everything works without a problem.
I tried the following regex a:contains('Backplane') which selects the first 8 categories on the link, but I was wondering if there no possibility for another selection that would allow me to select more (or more flexible) categories to scrape.
Can anyone help me with advice?
Thank you!
Url: https://www.digikey.com/products/en/connectors-interconnects/20
Sitemap:
{"_id":"digikey-connectors-interconnects","startUrl":["https://www.digikey.com/products/en/connectors-interconnects/20"],"selectors":[{"id":"digikey-category","type":"SelectorLink","parentSelectors":["_root"],"selector":"a.catfilterlink","multiple":true,"delay":0},{"id":"part-number","type":"SelectorTable","parentSelectors":["digikey-category","page"],"selector":"table#productTable","multiple":true,"columns":[{"header":"Compare Parts","name":"Compare Parts","extract":true},{"header":"Image","name":"Image","extract":true},{"header":"Digi-Key Part Number","name":"Digi-Key Part Number","extract":true},{"header":"Manufacturer Part Number","name":"Manufacturer Part Number","extract":true},{"header":"Manufacturer","name":"Manufacturer","extract":true},{"header":"Description","name":"Description","extract":true},{"header":"Quantity Available","name":"Quantity Available","extract":true},{"header":"Unit Price\n \n USD","name":"Unit Price\n \n USD","extract":false},{"header":"Minimum Quantity","name":"Minimum Quantity","extract":true},{"header":"Packaging","name":"Packaging","extract":true},{"header":"Series","name":"Series","extract":true},{"header":"Part Status","name":"Part Status","extract":true},{"header":"Convert From (Adapter End)","name":"Convert From (Adapter End)","extract":true},{"header":"Convert To (Adapter End)","name":"Convert To (Adapter End)","extract":true},{"header":"Mounting Type","name":"Mounting Type","extract":true}],"delay":0,"tableDataRowSelector":"#lnkPart tr","tableHeaderRowSelector":"#tblhead tr:nth-of-type(1)"},{"id":"page","type":"SelectorLink","parentSelectors":["digikey-category","page"],"selector":".mid-wrapper a.Next","multiple":false,"delay":0}]}