
Hey guys,
I want to scrape information from a new url link (for example Name and Street and opening times from a Store). Before I get to this link with that information, there is a page with all stores listed. For each Store there is already some information but you also have a "more information" button.
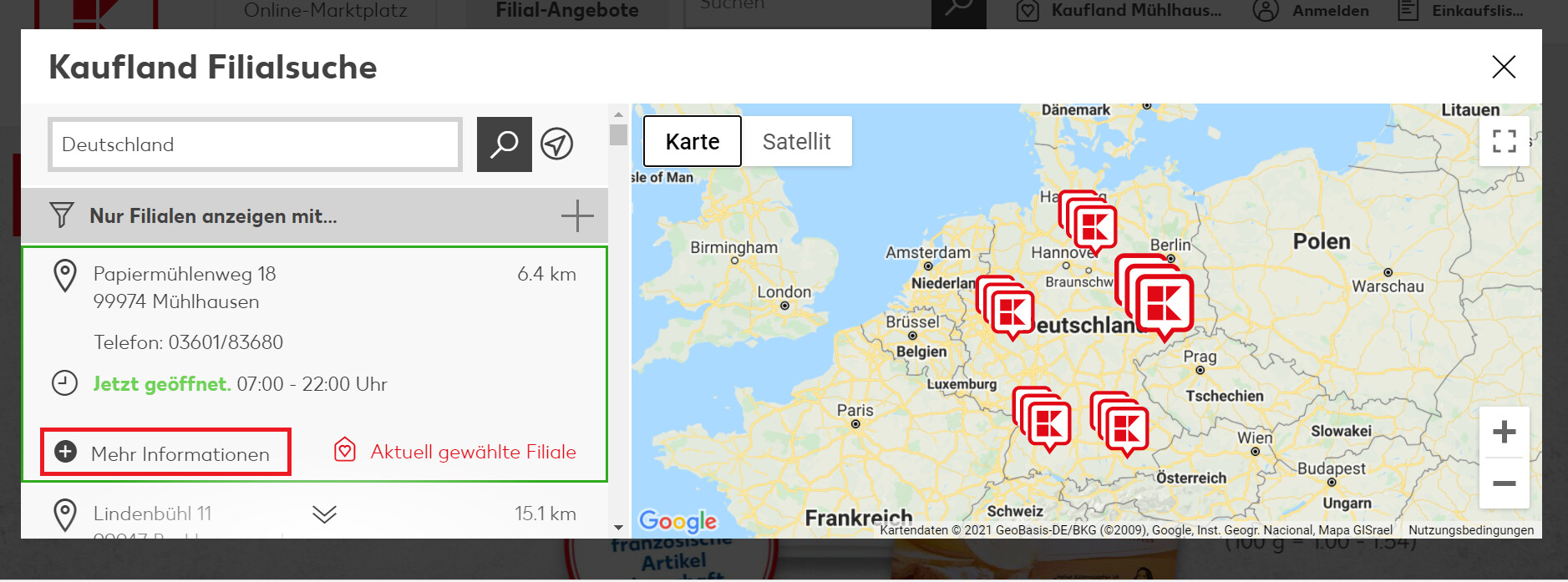
After you click on that "more information" button new data will appear including a link url "Detailseite", where I want to get informat from.
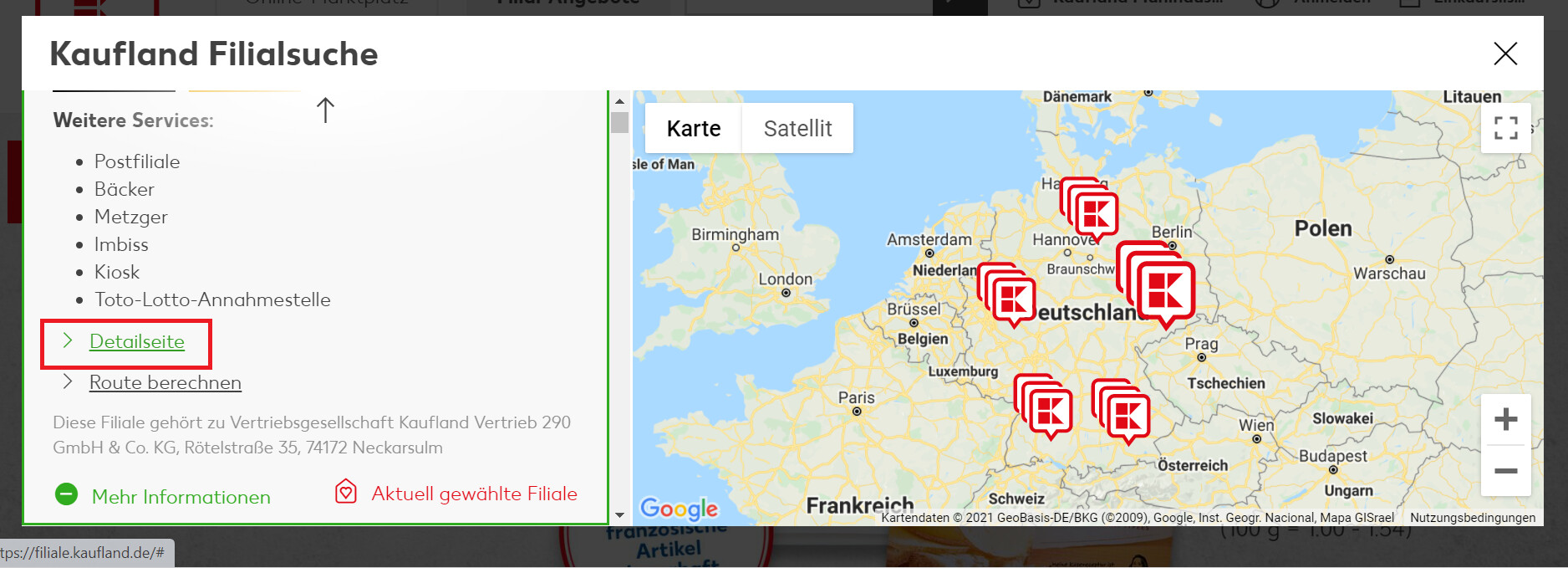
Then i want the scraper to open the link url "Detailseite" and extract the information (Name and Opening times) from the link url.
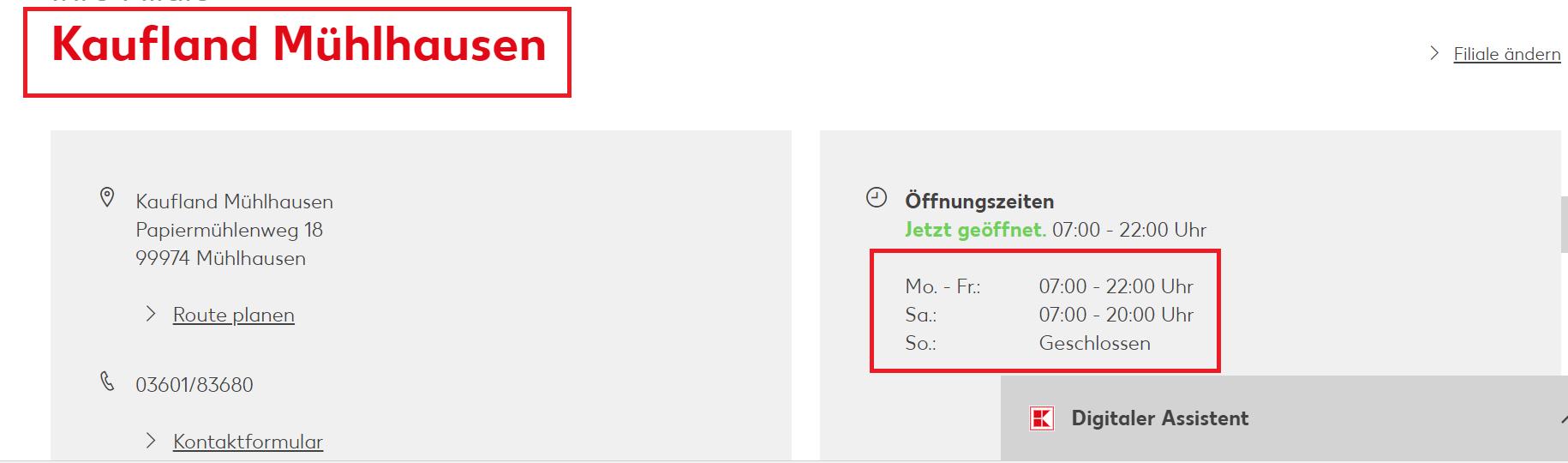
Therefore, I want the webscraper to repeat the extraction from each link, so in the end I basically have all information from each link "Detailseite" (from each store).
I hope somebody can help me with this topic and i'm looking forward to hear from you ideas.
Url: Angebote in meiner Nähe | Kaufland
Sitemap:
{"_id":"kaufland2","startUrl":["Angebote in meiner Nähe | Kauflandparent","multiple":true,"delay":2000,"clickElementSelector":"button","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"Detailseite","type":"SelectorLink","parentSelectors":["Mehrinformationen"],"selector":"a.a-link--store-list-detail","multiple":true,"delay":0},{"id":"Filiale","type":"SelectorText","parentSelectors":["Detailseite"],"selector":"h1","multiple":false,"regex":"","delay":0},{"id":"Öffnungszeitheute","type":"SelectorText","parentSelectors":["Detailseite"],"selector":"div.m-store-info__status","multiple":false,"regex":"","delay":0},{"id":"Öffnungszeiten","type":"SelectorText","parentSelectors":["Detailseite"],"selector":"dl","multiple":false,"regex":"","delay":0}]}