Hello everyone,
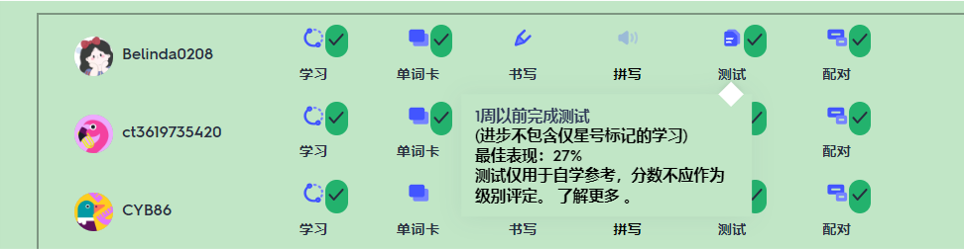
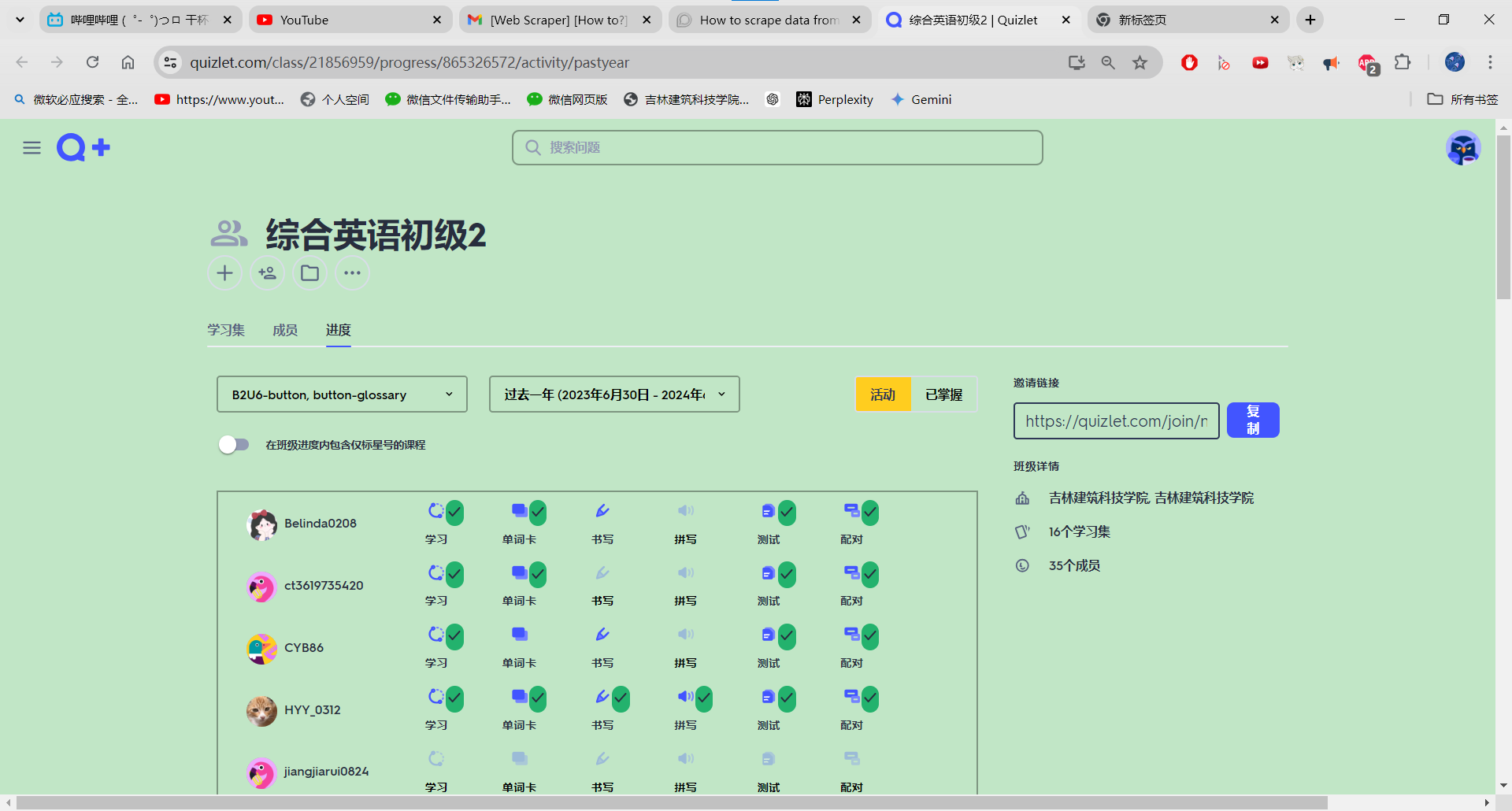
I'm hoping to get some assistance with a web scraping project I'm working on. I'm trying to scrape data from Quizlet's progress page, but I'm encountering some challenges.
Specifically, I'm unable to extract icons and click-to-reveal content items. I've tried using various web scraping techniques, but I haven't been successful in capturing these elements.
I'm not sure if this is a common issue or if I'm missing something specific in my approach. Any insights or guidance would be greatly appreciated.
Additionally, I'm unsure which forum category this question falls under. If there's a more appropriate category, please feel free to suggest it.
Thank you in advance for your help!