
Hi, I'm a newbie but I'm liking the tool so far.
The selector graph looks like a great tool to help troubleshoot my web scraping, but I can't find much information within the documentation on how to interpret the Selector Graph.
Based on the Web Scraper team's pagination video on youtube, it looks like I can see my pagination selector is working because my pagination selector appears several times in my graph.
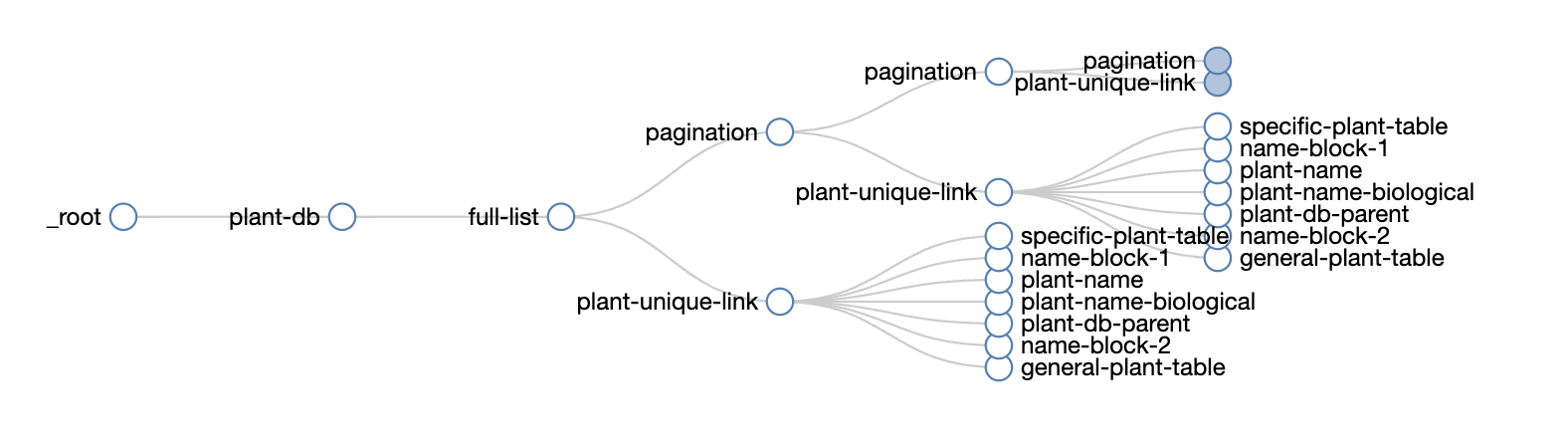
However, after my scraper is done going through all the pagination and plant-unique-link selectors, I expect it to go back to my plant-db selector and start all over again, until it is done going through all of the unique options listed in plant-db.
Because plant-db only appears once, it is fair for me to assume that the scaper will not go back to it to scrape all over variations?
Are there general guidelines to help me interpret the Selector Graph? It would be nice to use the graph to confirm if I set my scraper up correctly instead of trial/error, so I'm not sending unnecessary traffic to the website's pages that I'm trying to crawl.
Thank you for any guidelines or advice.
Sitemap:
{"_id":"garden-org","startUrl":["https://garden.org/plants/group/"],"selectors":[{"id":"plant-db","multiple":true,"parentSelectors":["_root"],"selector":"td a","type":"SelectorLink"},{"id":"full-list","multiple":false,"parentSelectors":["plant-db"],"selector":".col-md-6 > div .card-body > a:nth-of-type(1)","type":"SelectorLink"},{"id":"pagination","multiple":true,"parentSelectors":["full-list","pagination"],"selector":"nav:nth-of-type(1) a.page-link","type":"SelectorLink"},{"id":"plant-unique-link","multiple":true,"parentSelectors":["full-list","pagination"],"selector":"tr:nth-of-type(n+2) td:nth-of-type(2) a","type":"SelectorLink"},{"id":"specific-plant-table","multiple":false,"parentSelectors":["plant-unique-link"],"regex":"","selector":"#ngabody > div:nth-child(2) > div > div.row > div.col-lg-8 > table > tbody","type":"SelectorHTML"},{"id":"name-block-1","multiple":false,"parentSelectors":["plant-unique-link"],"regex":"","selector":".col-lg-4 div:nth-of-type(2)","type":"SelectorHTML"},{"id":"plant-name","multiple":false,"parentSelectors":["plant-unique-link"],"regex":"","selector":"li.active","type":"SelectorText"},{"id":"plant-name-biological","multiple":false,"parentSelectors":["plant-unique-link"],"regex":"","selector":".breadcrumb-item i","type":"SelectorText"},{"id":"plant-db-parent","multiple":false,"parentSelectors":["plant-unique-link"],"regex":"","selector":".breadcrumb-item a","type":"SelectorText"},{"id":"name-block-2","multiple":false,"parentSelectors":["plant-unique-link"],"regex":"","selector":".col-lg-4 div:nth-of-type(3)","type":"SelectorHTML"},{"id":"general-plant-table","multiple":false,"parentSelectors":["plant-unique-link"],"regex":"","selector":"table:nth-of-type(2) tbody","type":"SelectorHTML"}]}