Why I am not able to grab/follow the links of the search results of this search engine?
(if it helps here there is the same search engine in english language too: Italian Business Register | Italian companies official data )
The url has a token in the search results, so to update the sitemap link and to get the search results you shoudl do that:
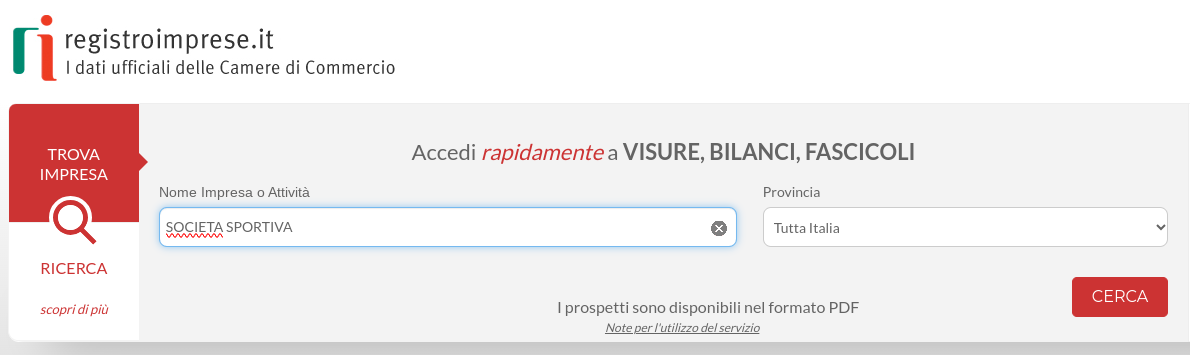
- Go to Registro Imprese | I dati Ufficiali della Camera di Commercio
and then enter this text "SOCIETA SPORTIVA" into the field "Nome Impresa o Attività" and then click on the button "CERCA":
then you will see the search results:
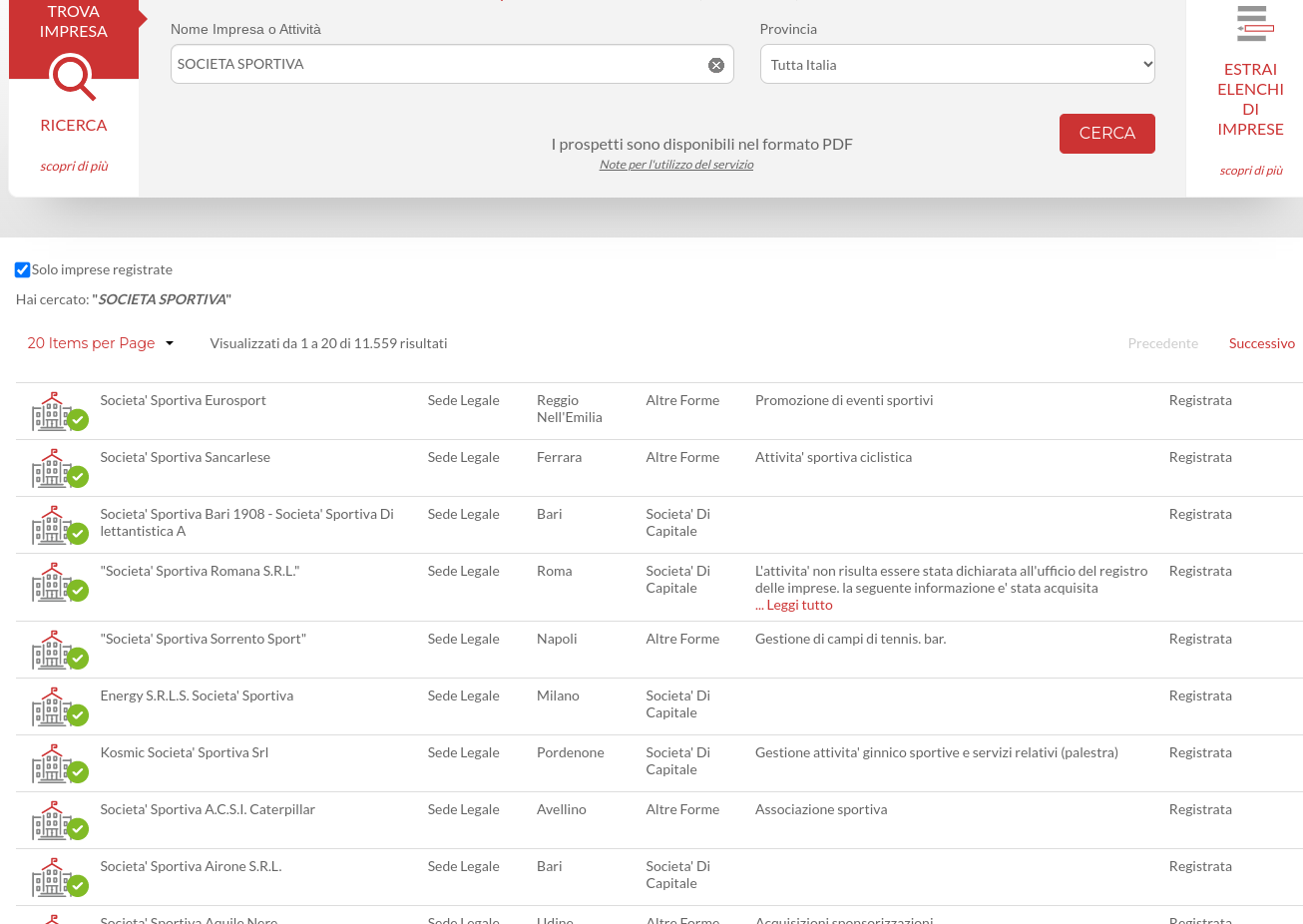
Url: Registro Imprese | I dati Ufficiali della Camera di Commercio
Sitemap:
{"_id":"registroimprese-it","startUrl":["https://www.registroimprese.it/ricerca-libera-e-acquisto?p_p_id=ricercaportlet_WAR_ricercaRIportlet&p_p_lifecycle=0&p_p_state=normal&_ricercaportlet_WAR_ricercaRIportlet_cur=1&_ricercaportlet_WAR_ricercaRIportlet_pageToken=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE2OTU0Nzk5MzEsImNvdW50IjoyNTB9.D5gR7-2Z8yXIA6PDJXMgGhPubFMyQ2RNSi_n_1_4HEA"],"selectors":[{"id":"page","paginationType":"clickMore","parentSelectors":["_root","page"],"selector":"#_ricercaportlet_WAR_ricercaRIportlet_BrPageIteratorBottom .pager li:nth-of-type(3) a","type":"SelectorPagination"}]}