Hello everyone,
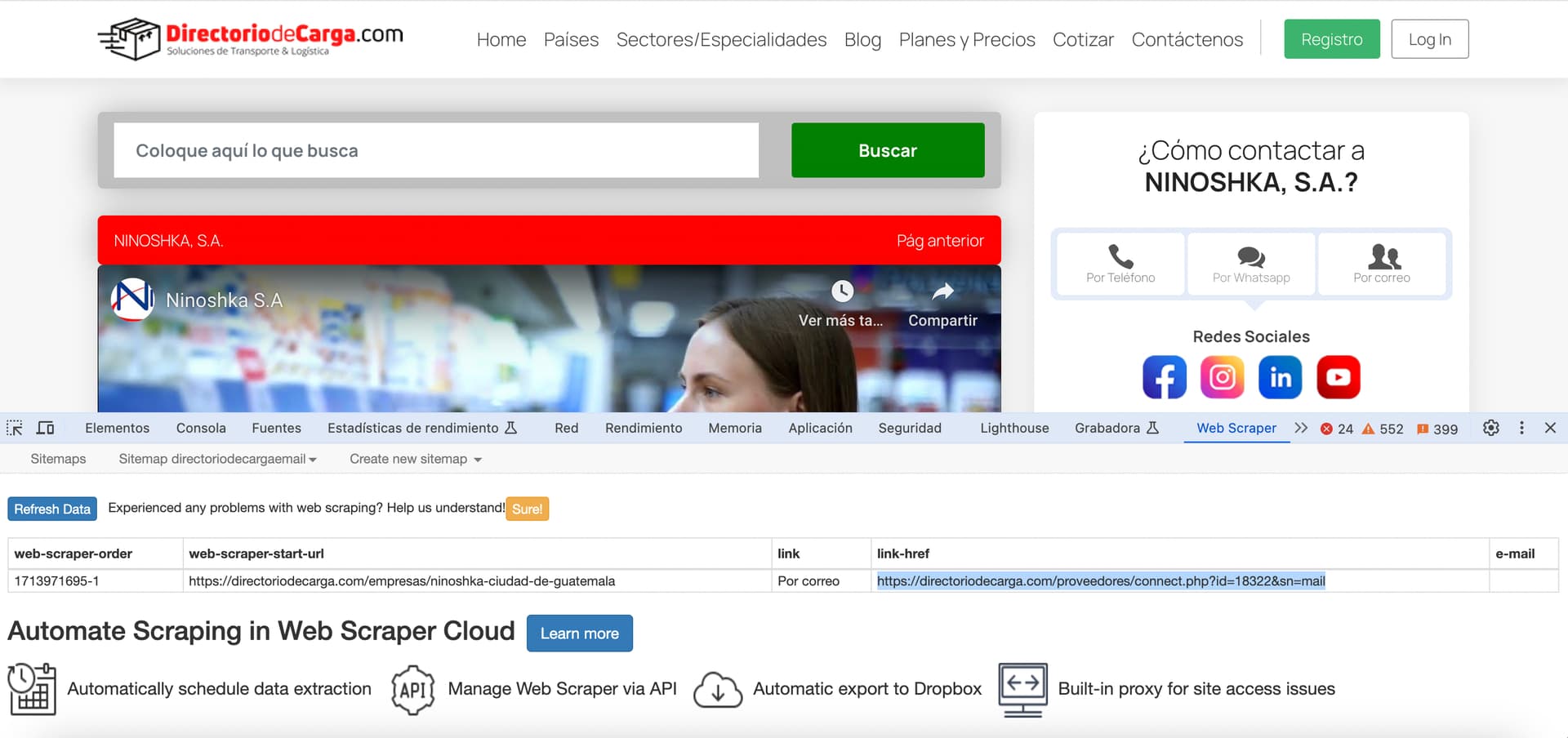
I've encountered a challenging scenario while attempting to scrape email addresses for a large dataset of over 15,000 companies. The emails are not listed in plaintext in the HTML source code. Instead, they are displayed as an image, and when clicked, a JavaScript function makes an AJAX request that, I believe, fetches the email address.
Here’s what happens step-by-step:
- A click on the image seems to trigger a JavaScript function.
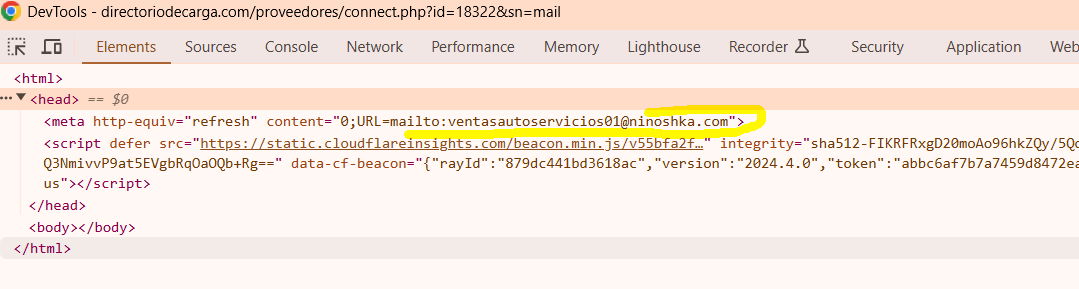
- No
mailto:or direct email link is present in the source code. - The actual email link is possibly being retrieved by an AJAX call to a PHP script.
- The email address is likely returned from the server in response to the AJAX request, but it's not visible in the HTML or the page's source code.
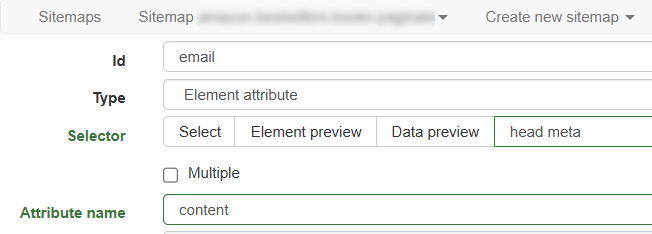
I have tried using WebScraper.io to simulate the click and capture the resulting AJAX request, but the data preview showed nothing, suggesting that the email is fetched and rendered dynamically.
Url: Ninoshka, S.a. | DirectorioDeCarga.com
Sitemap:
{"_id":"directorio-de-carga","startUrl":[""],"selectors":[{"id":"pagination","parentselectors":["_root","pagination"],"paginationtype":"auto","type":"selectorpagination","selector":".pagination_fg en DirectorioDeCarga.com a"},{"id":"element-card","parentSelectors":["Pagination"],"type":"SelectorElement","selector":"div.content","multiple":true},{"id":"Nombre-de-la-empresa","parentSelectors":["element-card"],"type":"SelectorText","selector":"strong","multiple":false,"regex":""},{"id":"Dirección-de-la-empresa","parentSelectors":["element-card"],"type":"SelectorText","selector":"p","multiple":false,"regex":""},{"id":"País","parentSelectors":["element-card"],"type":"SelectorText","selector":"h6","multiple":false,"regex":""},{"id":"Link-del-directorio","parentSelectors":["element-card"],"type":"SelectorLink","selector":".title a","multiple":false,"linkType":"linkFromHref"},{"id":"Website","parentSelectors":["Link-del-directorio"],"type":"SelectorText","selector":"strong span","multiple":false,"regex":""},{"id":"Telefono","parentSelectors":["Link-del-directorio"],"type":"SelectorText","selector":"li:nth-of-type(6) strong","multiple":false,"regex":"Teléfono\(s\):\s*\+\d{3}\s\d{4}-\d{4}"},{"id":"emailClick","parentSelectors":["Link-del-directorio"],"type":"SelectorElementClick","clickActionType":"real","clickElementSelector":"li:nth-of-type(3) label a","clickElementUniquenessType":"uniqueText","clickType":"clickOnce","delay":2000,"discardInitialElements":"do-not-discard","multiple":true,"selector":"li:nth-of-type(3) label a"},{"id":"emailExtract","parentSelectors":["emailClick"],"type":"SelectorElementAttribute","selector":"a","multiple":false,"extractAttribute":"href"}]}