
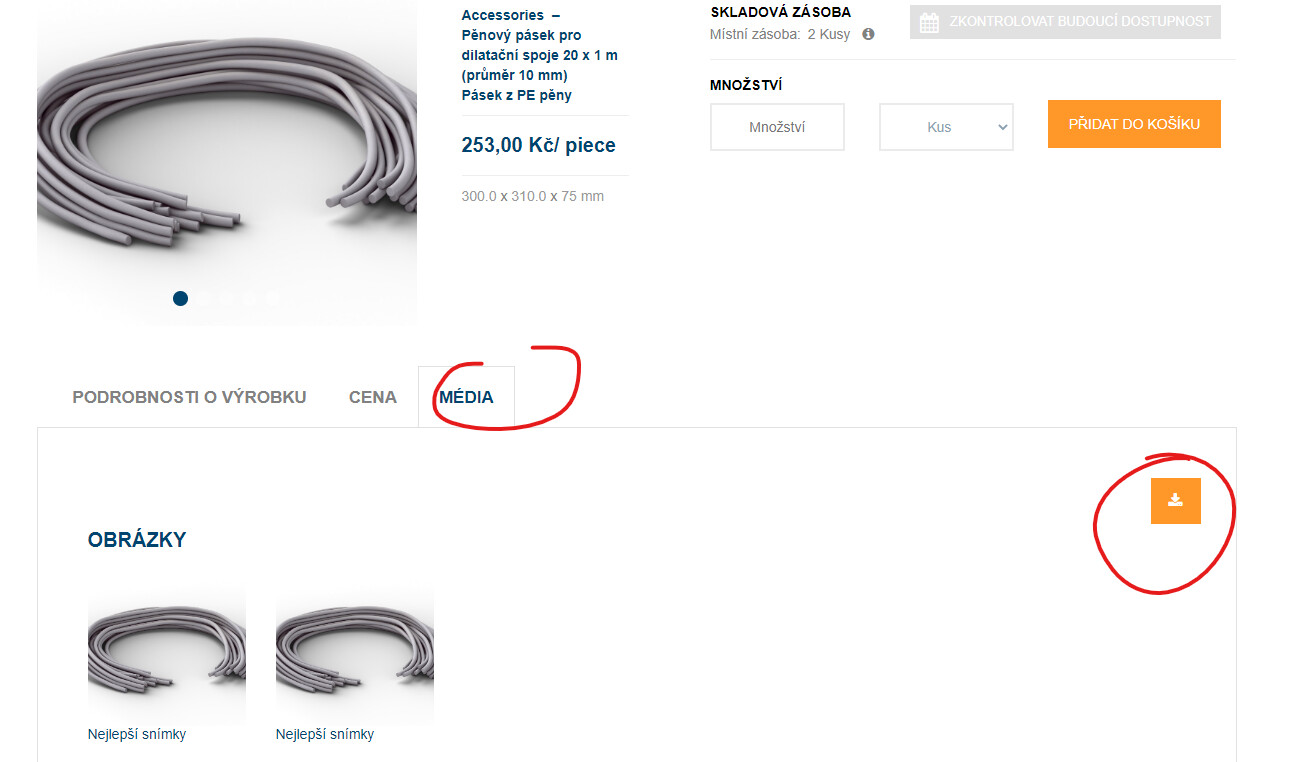
Hi, I'm downloading product data from a B2B system, and I can't figure out how to download the URL link to the associated .zip file. I would need to download bulk links, which I would then have downloaded via a free download manager. Please help me what type of selector should I choose to list the URL of the related file. I am attaching pictures. Thank you
Sitemap:
{"_id":"quick-step-prislusenstvi","startUrl":["Login | Rowflooring Site CZ strong, .bottom a","type":"SelectorPagination"},{"id":"link","parentSelectors":["pagination"],"type":"SelectorLink","selector":".productInfo a","multiple":true},{"id":"ean","parentSelectors":["link"],"type":"SelectorText","selector":"#ean span","multiple":false,"regex":""},{"id":"vyrobek","parentSelectors":["link"],"type":"SelectorText","selector":"#name span","multiple":false,"regex":""},{"id":"obchodni-kod","parentSelectors":["link"],"type":"SelectorText","selector":"#commercialCode span","multiple":false,"regex":""},{"id":"rozsah","parentSelectors":["link"],"type":"SelectorText","selector":"#commercialRange span","multiple":false,"regex":""},{"id":"skupina-vyrobku","parentSelectors":["link"],"type":"SelectorText","selector":"#productGroup span","multiple":false,"regex":""},{"id":"cislo-db","parentSelectors":["link"],"type":"SelectorText","selector":"#dbNumber span","multiple":false,"regex":""},{"id":"cislo-nobb","parentSelectors":["link"],"type":"SelectorText","selector":"#nobbNumber span","multiple":false,"regex":""},{"id":"typ-prislusenstvi","parentSelectors":["link"],"type":"SelectorText","selector":"#accessoryType span","multiple":false,"regex":""},{"id":"nosny-material","parentSelectors":["link"],"type":"SelectorText","selector":"#carrier span","multiple":false,"regex":""},{"id":"domaci-zaruka","parentSelectors":["link"],"type":"SelectorText","selector":"#domesticWarranty span","multiple":false,"regex":""},{"id":"podlahove-vytapeni","parentSelectors":["link"],"type":"SelectorText","selector":"#underfloorHeating i","multiple":false,"regex":""},{"id":"podlahove-chlazeni","parentSelectors":["link"],"type":"SelectorText","selector":"#underfloorCooling i","multiple":false,"regex":""},{"id":"pefc","parentSelectors":["link"],"type":"SelectorText","selector":"#pefc span","multiple":false,"regex":""},{"id":"delka","parentSelectors":["link"],"type":"SelectorText","selector":"#length span:nth-of-type(1)","multiple":false,"regex":""},{"id":"sirka","parentSelectors":["link"],"type":"SelectorText","selector":"#width span:nth-of-type(1)","multiple":false,"regex":""},{"id":"tloustka","parentSelectors":["link"],"type":"SelectorText","selector":"#thickness span:nth-of-type(1)","multiple":false,"regex":""},{"id":"m-na-palete","parentSelectors":["link"],"type":"SelectorText","selector":"#metersPerPallet span","multiple":false,"regex":""},{"id":"baleni-na-palete","parentSelectors":["link"],"type":"SelectorText","selector":"#packsPerPallet span","multiple":false,"regex":""},{"id":"baleni-celkova-hmotnost","parentSelectors":["link"],"type":"SelectorText","selector":"#packGrossWeight span:nth-of-type(1)","multiple":false,"regex":""},{"id":"baleni-delka","parentSelectors":["link"],"type":"SelectorText","selector":"#packLength span:nth-of-type(1)","multiple":false,"regex":""},{"id":"baleni-sirka","parentSelectors":["link"],"type":"SelectorText","selector":"#packWidth span:nth-of-type(1)","multiple":false,"regex":""},{"id":"baleni-vyska","parentSelectors":["link"],"type":"SelectorText","selector":"#packHeight span:nth-of-type(1)","multiple":false,"regex":""},{"id":"baleni-hmotnost","parentSelectors":["link"],"type":"SelectorText","selector":"#packWeight span:nth-of-type(1)","multiple":false,"regex":""},{"id":"price","parentSelectors":["link"],"type":"SelectorText","selector":"p.big-price","multiple":false,"regex":""},{"id":"files-url","parentSelectors":["link"],"type":"SelectorPopupLink","selector":"i.fa-download","multiple":false}]}
