
How to scrape all the year link ( Main URL only) serial wise.
Url: https://journals.sagepub.com/loi/AAC
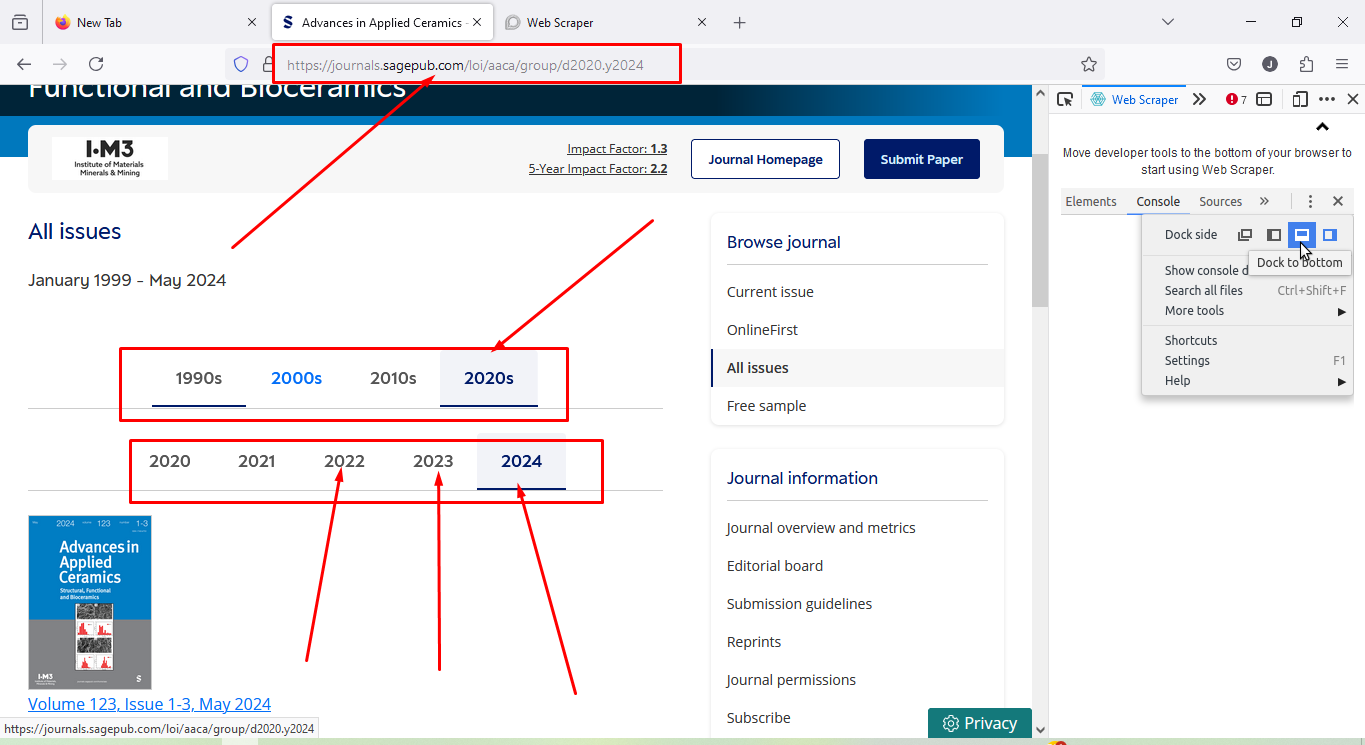
Sitemap:
{"_id":"sage_issue","startUrl":["https://journals.sagepub.com/loi/AAC"],"selectors":[{"id":"element","parentSelectors":["_root"],"type":"SelectorElementClick","clickActionType":"real","clickElementSelector":"a[data-id='loi-decade']","clickElementUniquenessType":"uniqueText","clickType":"clickOnce","delay":2000,"discardInitialElements":"do-not-discard","multiple":true,"selector":"body"},{"id":"ele2","parentSelectors":["element"],"type":"SelectorElementClick","clickActionType":"real","clickElementSelector":".active .tab__nav__item a","clickElementUniquenessType":"uniqueText","clickType":"clickOnce","delay":2000,"discardInitialElements":"do-not-discard","multiple":true,"selector":"parent"},{"id":"link","parentSelectors":["ele2"],"type":"SelectorLink","selector":"#pane-fe0a3568-0a5d-4083-8340-688f1170c354-d2020-y2023 a","multiple":true,"linkType":"linkFromHref"}]}