I have problems again with the pagination. Anybody can help ?
Url: https://ranking-empresas.eleconomista.es/ranking_empresas_nacional.html
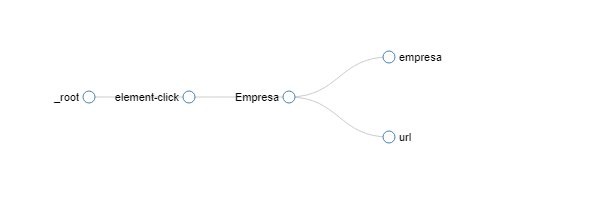
Sitemap:
{"_id":"eleconomista","startUrl":["https://ranking-empresas.eleconomista.es/ranking_empresas_nacional.html"],"selectors":[{"id":"Empresa","type":"SelectorLink","parentSelectors":["_root"],"selector":"td.tal a","multiple":true,"delay":0},{"id":"empresa","type":"SelectorText","parentSelectors":["Empresa"],"selector":"tr.even:contains('Denominación') td.tal:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"url","type":"SelectorLink","parentSelectors":["Empresa"],"selector":"tr.even:contains('Página Web') a.url","multiple":false,"delay":0},{"id":"pagination","type":"SelectorLink","parentSelectors":["_root"],"selector":"li:nth-of-type(6) a","multiple":true,"delay":0}]}