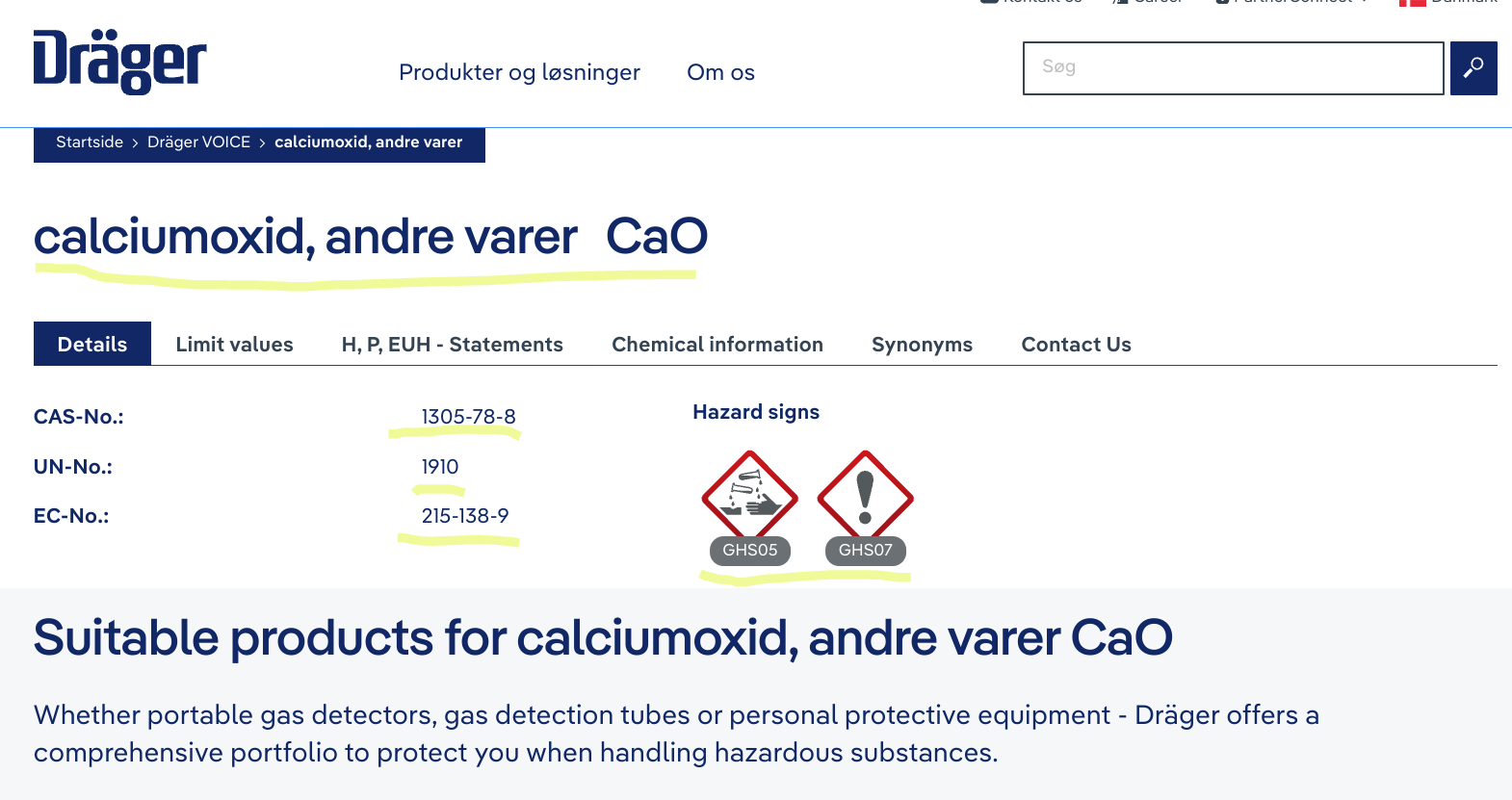
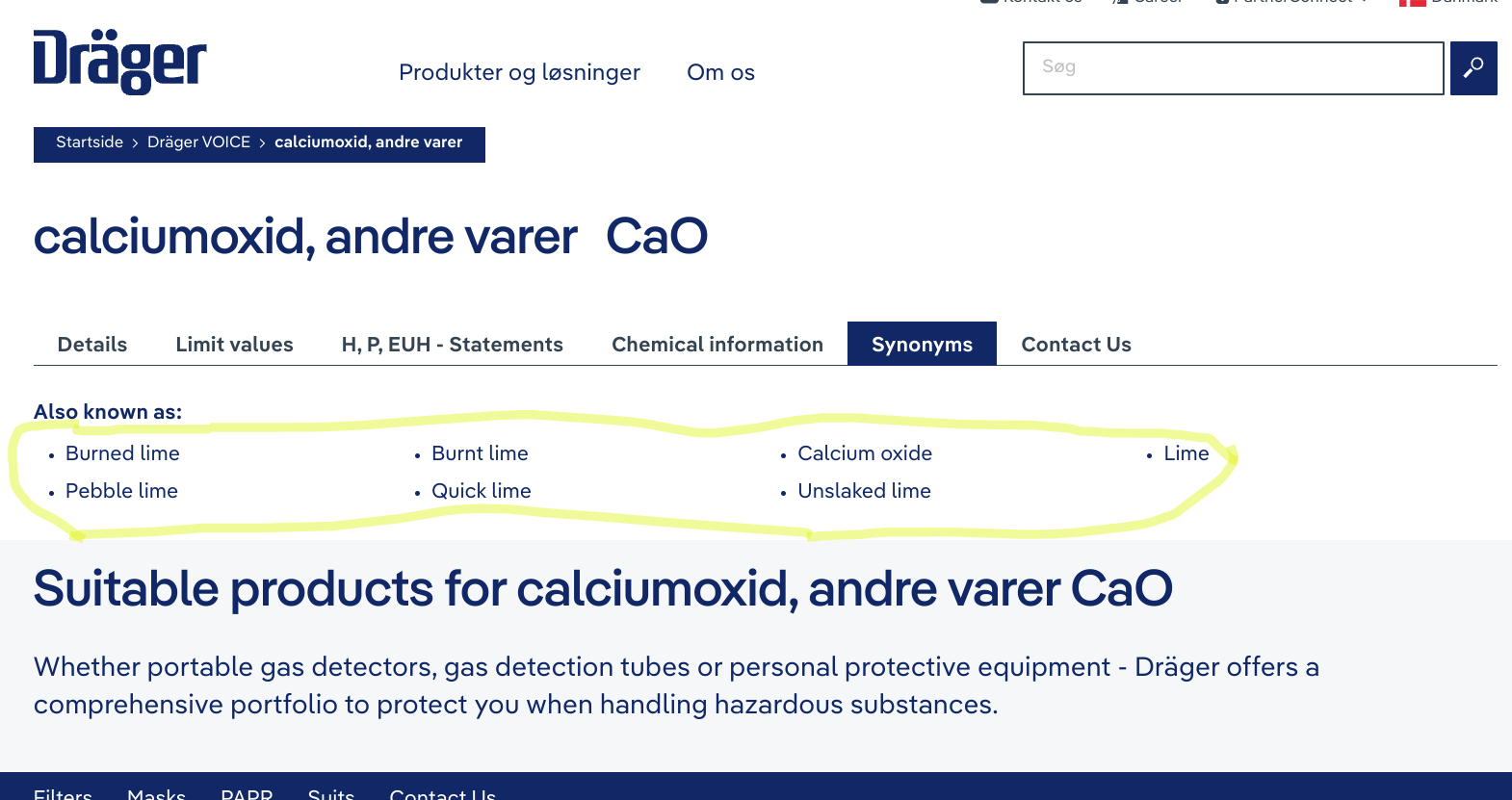
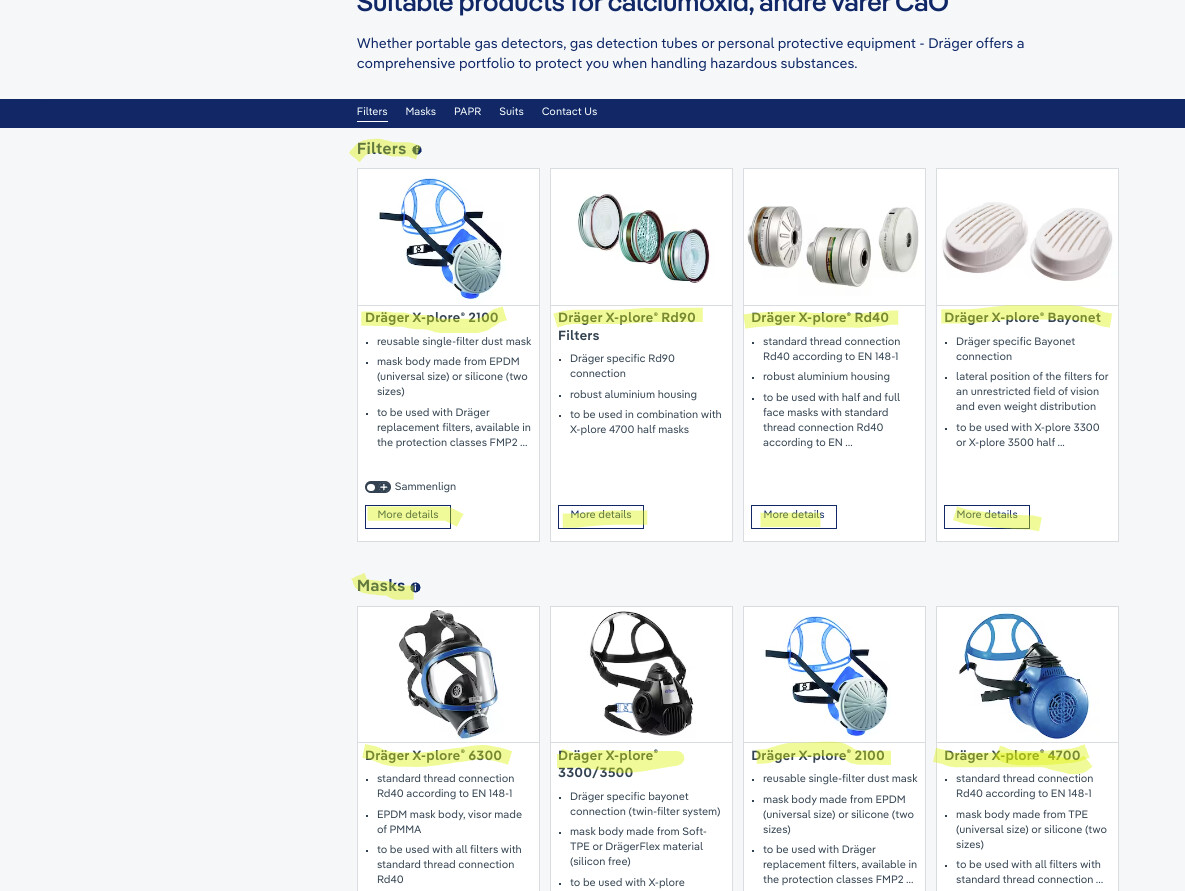
Is it possible to scrape from a xml sitemap like this: https://www.draeger.com/da_dk/Sitemap.xml
I want it to access each url and fetch data on each url.
The plugin is just giving me following error:
FAILED_TO_CONNECT_TO_CHROME_TAB {"message":"Could not establish connection. Receiving end does not exist."}
So i suspect that they may have some form of bot/scrape protection maybe.