Hi all,
I am trying to scrape some info from the following site: Search Results
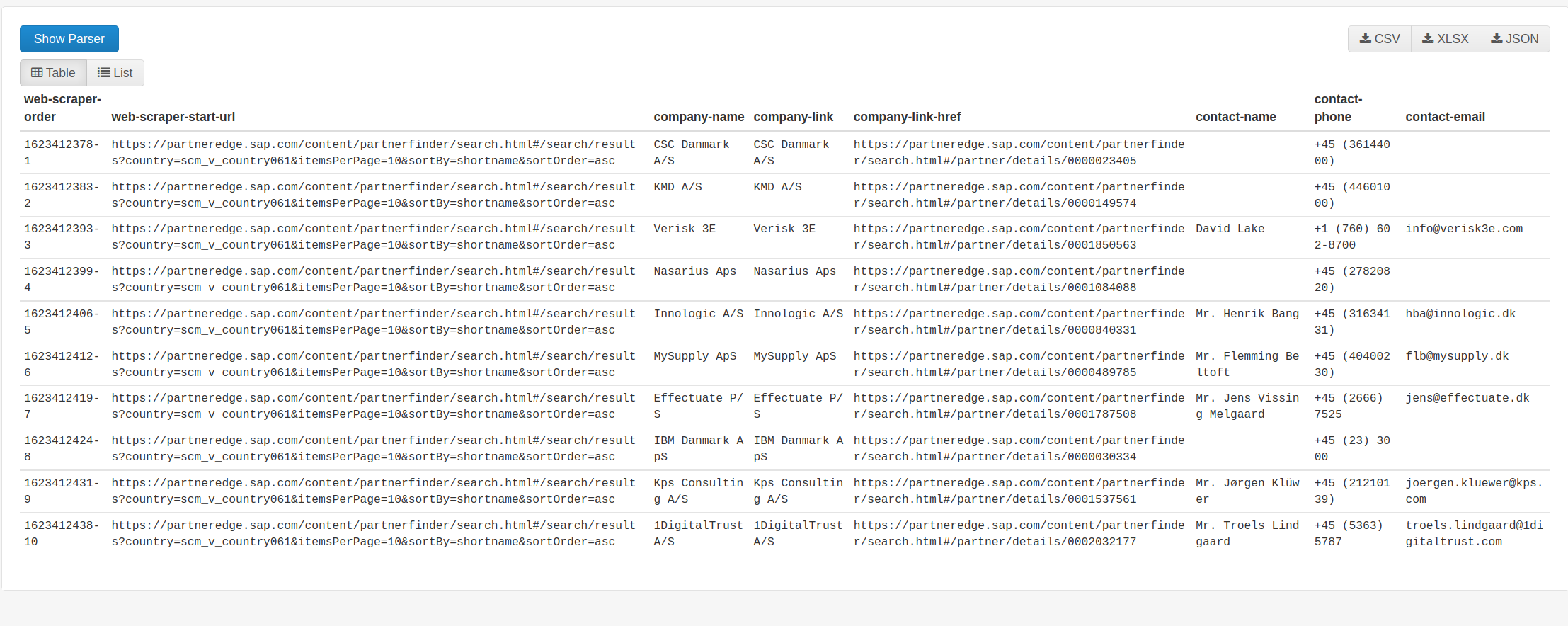
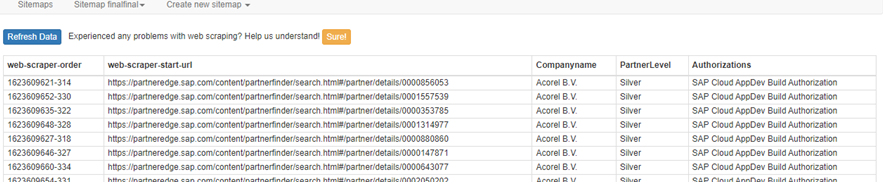
I managed to let the scraper expand the list and find the desired links (namely the clickable company names). Now I want to scrape some info from the page of every company link (for simplicity lets say I want to scrape every company name from the company link), but scraper returns the name of the last company for all company links! Anyone know how to solve?
Sitemap:
{"_id":"sapcompaniesdenmark","startUrl":["Search Results p","clickType":"clickMore","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueCSSSelector"},{"id":"SelectCompanyLinkInsideWrapper","type":"SelectorLink","parentSelectors":["ExpandListAndSelectCompanyWrappers"],"selector":".search-result__head a","multiple":false,"delay":0},{"id":"SaveName","type":"SelectorText","parentSelectors":["SelectCompanyLinkInsideWrapper"],"selector":".partner-details section:nth-of-type(1) header","multiple":false,"regex":"","delay":0}]}