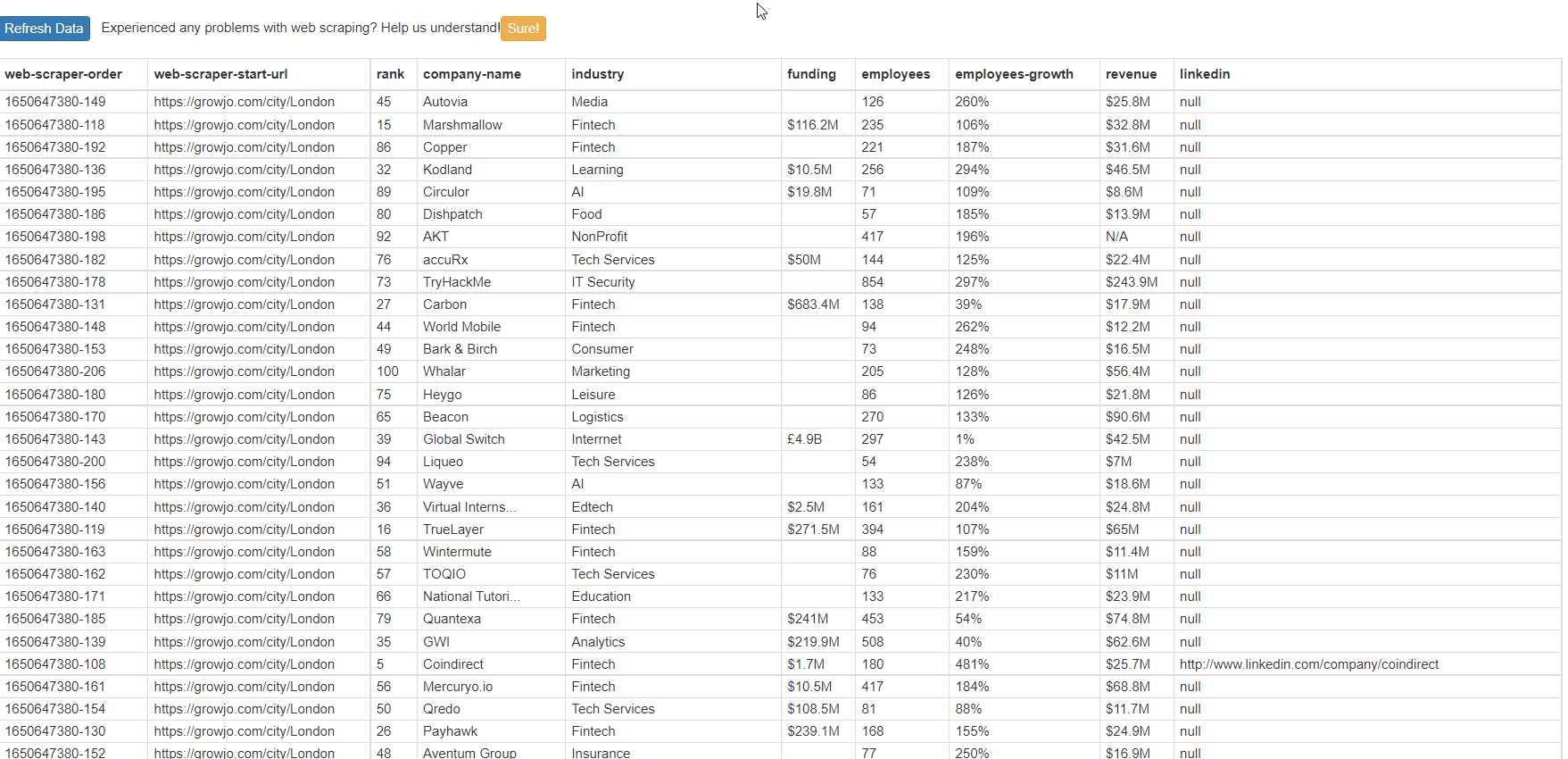
I have a list there of 500 companies from London
Table scrapes nicely data EXCEPT that LinkedIn link to company's profile.
How can I add that to the table?

I have a list there of 500 companies from London
Table scrapes nicely data EXCEPT that LinkedIn link to company's profile.
How can I add that to the table?
@ATTV Hi, in order to do that you can use an 'Element attribute' selector - a[href*="http://www.linkedin.com/company"] with an 'Attribute name' - href.
Example:
{"_id":"growjo-com","startUrl":["https://growjo.com/city/London"],"selectors":[{"delay":0,"id":"wrapper","multiple":true,"parentSelectors":["_root"],"selector":"tbody tr","type":"SelectorElement"},{"delay":0,"id":"rank","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(1)","type":"SelectorText"},{"delay":0,"id":"company-name","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(2)","type":"SelectorText"},{"delay":0,"id":"industry","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(3)","type":"SelectorText"},{"delay":0,"id":"funding","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(4)","type":"SelectorText"},{"delay":0,"id":"employees","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(5)","type":"SelectorText"},{"delay":0,"id":"employees-growth","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(6)","type":"SelectorText"},{"delay":0,"id":"revenue","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(7)","type":"SelectorText"},{"delay":0,"extractAttribute":"href","id":"linkedin","multiple":false,"parentSelectors":["wrapper"],"selector":"a[href*=\"http://www.linkedin.com/company\"]","type":"SelectorElementAttribute"}]}
@ATTV It seems that it takes a while to fully load, therefore you should implement ''Element scroll'' selector.
{"_id":"growjo-com","startUrl":["https://growjo.com/city/London"],"selectors":[{"delay":2000,"id":"wrapper","multiple":true,"parentSelectors":["_root"],"selector":"tbody tr","type":"SelectorElementScroll"},{"delay":0,"id":"rank","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(1)","type":"SelectorText"},{"delay":0,"id":"company-name","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(2)","type":"SelectorText"},{"delay":0,"id":"industry","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(3)","type":"SelectorText"},{"delay":0,"id":"funding","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(4)","type":"SelectorText"},{"delay":0,"id":"employees","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(5)","type":"SelectorText"},{"delay":0,"id":"employees-growth","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(6)","type":"SelectorText"},{"delay":0,"id":"revenue","multiple":false,"parentSelectors":["wrapper"],"regex":"","selector":"td:nth-of-type(7)","type":"SelectorText"},{"delay":0,"extractAttribute":"href","id":"linkedin","multiple":false,"parentSelectors":["wrapper"],"selector":"a[href*=\"http://www.linkedin.com/company\"]","type":"SelectorElementAttribute"}]}
Not everything was scraped still, but those are a very few missing links now, so probably I can change the time of the scroll and it should work. So great, thank you!
I'm a bit worried though I don't know this element attribute thing - do I get t right? It's used to scrape any element I want after I click on "inspect" and find... something in the code? (not sure what I should be paying attention to). Do we have some tutorial for that?
@ATTV Yes, this one should help you understanding how exactly it works - Web Scraper << How to >> Extract data from element attribute