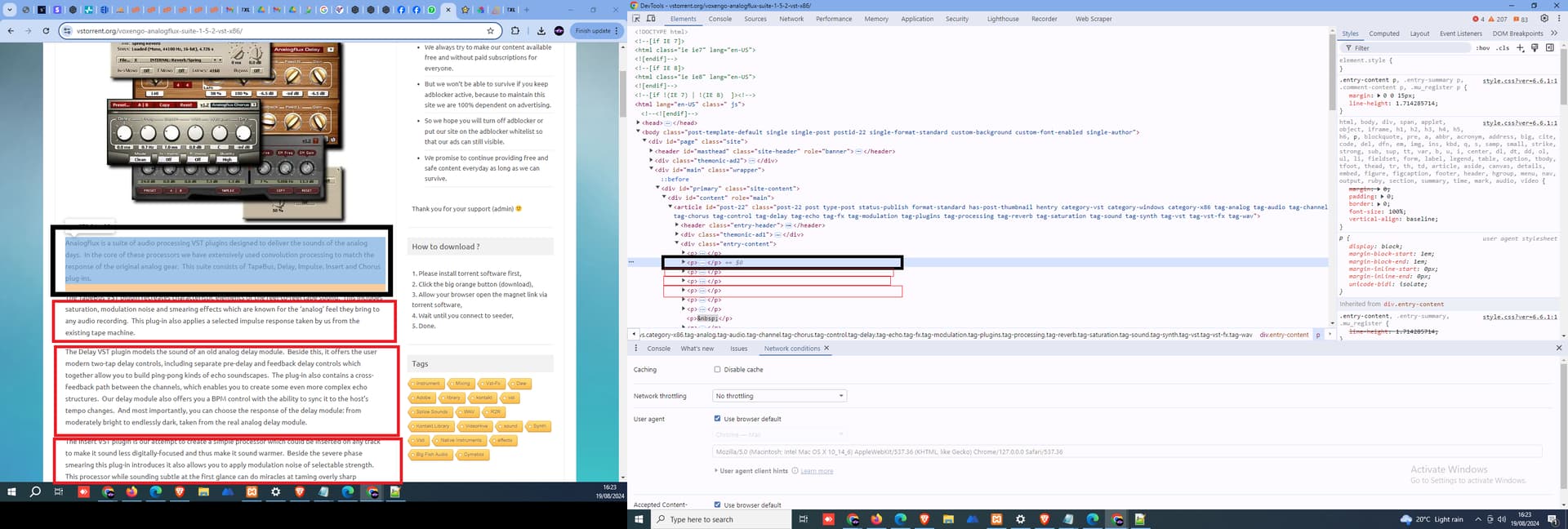
Hi all. im trying to scrape content from this website
currently im having to grab the RAW text from DIV -
But i would prefere if i could grab the
text just from the
tags
as it is im grabbing raw text and its just messy, grabbing alot of other junk
So if anybody could help, how would i grab the just
or
text
thank you
heres my current scrape JSON
{"_id":"audioloveandgenreVstorrent","startUrl":["https://vstorrent.org/page/[0-1495]"],"selectors":[{"id":"linker","parentSelectors":["wrapper"],"type":"SelectorLink","selector":".entry-title a","multiple":false,"linkType":"linkFromHref"},{"id":"title","parentSelectors":["linker"],"type":"SelectorText","selector":"h1","multiple":false,"regex":""},{"id":"image","parentSelectors":["linker"],"type":"SelectorImage","selector":"img","multiple":false},{"id":"info","parentSelectors":["linker"],"type":"SelectorText","selector":"div.entry-content","multiple":false,"regex":""},{"id":"fileinfo","parentSelectors":["linker"],"type":"SelectorText","selector":"X","multiple":false,"regex":""},{"id":"catagory","parentSelectors":["linker"],"type":"SelectorText","selector":"div.categories","multiple":false,"regex":""},{"id":"dateadded","parentSelectors":["linker"],"type":"SelectorText","selector":"span.date","multiple":false,"regex":""},{"id":"video","parentSelectors":["linker"],"type":"SelectorHTML","selector":"div.articletxt","multiple":false,"regex":"YouTube[^" ]+"},{"id":"soundcloud","parentSelectors":["linker"],"type":"SelectorHTML","selector":".soundcloudclass","multiple":false,"regex":"https://w.soundcloud.com/player/[^" ]+"},{"id":"mp3","parentSelectors":["linker"],"type":"SelectorHTML","selector":".dleaudioplayer","multiple":false,"regex":"https://cdn-prd.sounds.com[^" ]+"},{"id":"download","parentSelectors":["linker"],"type":"SelectorElementAttribute","selector":".code-block a[data-wpel-link]","multiple":false,"extractAttribute":"href"},{"id":"wrapper","parentSelectors":["_root"],"type":"SelectorElement","selector":"article","multiple":true},{"id":"tags","parentSelectors":["linker"],"type":"SelectorText","selector":"div.tags","multiple":false,"regex":""},{"id":"image2","parentSelectors":["linker"],"type":"SelectorElementAttribute","selector":".entry-content p:nth-of-type(1) a","multiple":false,"extractAttribute":"href"},{"id":"image3","parentSelectors":["linker"],"type":"SelectorElementAttribute","selector":"p:nth-of-type(4) a","multiple":false,"extractAttribute":"href"},{"id":"image4","parentSelectors":["linker"],"type":"SelectorElementAttribute","selector":"p:nth-of-type(9) a","multiple":false,"extractAttribute":"href"},{"id":"image5","parentSelectors":["linker"],"type":"SelectorElementAttribute","selector":"p:nth-of-type(12) a","multiple":false,"extractAttribute":"href"},{"id":"image6","parentSelectors":["linker"],"type":"SelectorElementAttribute","selector":"p:nth-of-type(15) a","multiple":false,"extractAttribute":"href"},{"id":"image7","parentSelectors":["linker"],"type":"SelectorElementAttribute","selector":"p:nth-of-type(18) a","multiple":false,"extractAttribute":"href"}]}