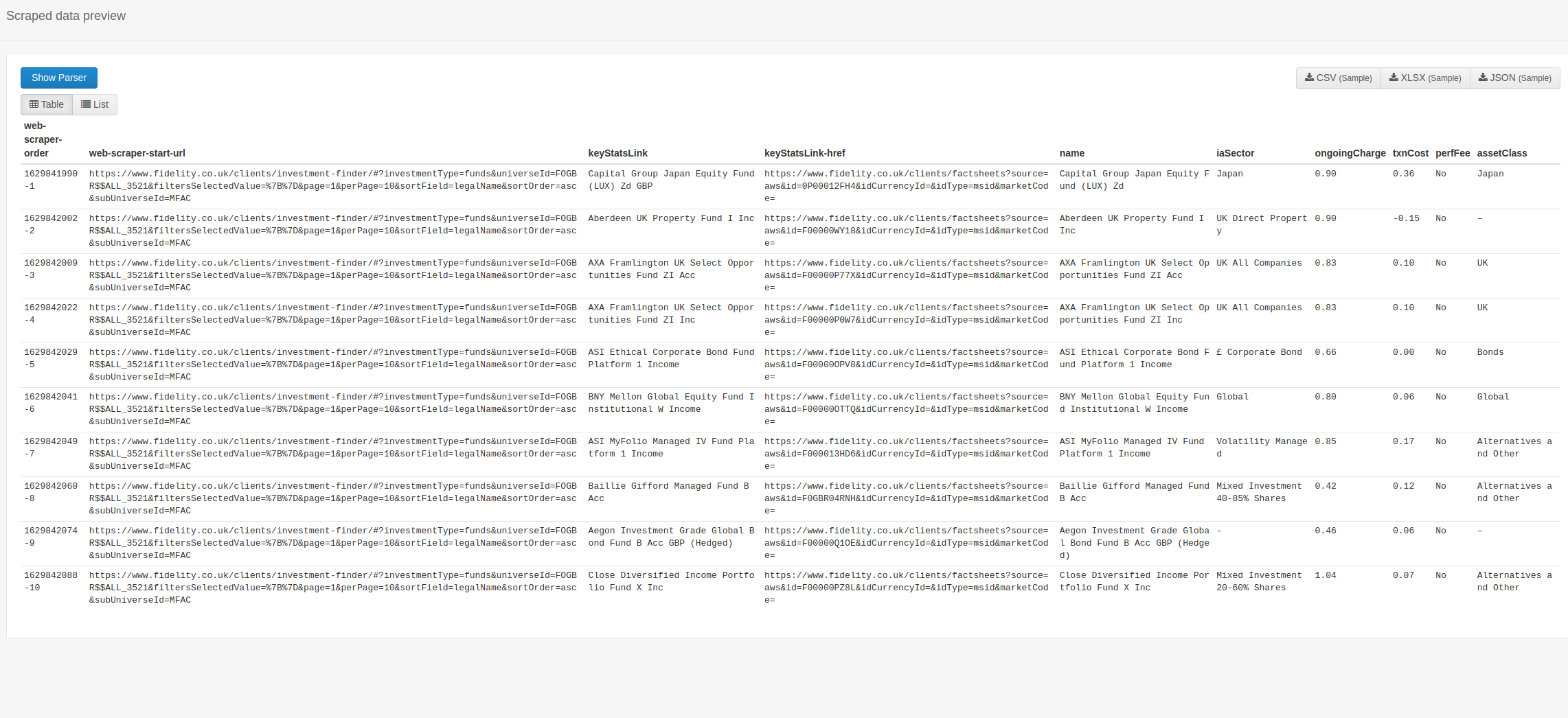
I am a Fidelity customer and should review my portfolio periodically, so I need to extract some key data from their fund factsheets…
On their website there is a paginated table of these factsheets (3,611 as I write) containing links to further detailed data on each fund.
I have managed to paginate through the whole table and extract the higer-level data, and also the url to follow for the more detailed data. (sitemap1).
{"_id":"fidelity-test1","startUrl":["https://www.fidelity.co.uk/clients/investment-finder/#?investmentType=funds&universeId=FOGBR$$ALL_3521&filtersSelectedValue={}&page=[1-74]&perPage=50&sortField=legalName&sortOrder=asc&subUniverseId=MFAC"],"selectors":[{"id":"tableBody","type":"SelectorElement","parentSelectors":["_root"],"selector":".ec-section__content--table-securities tbody","multiple":false,"delay":0},{"id":"tableRow","type":"SelectorElement","parentSelectors":["tableBody"],"selector":"tr","multiple":true,"delay":0},{"id":"keyStatsLink","type":"SelectorLink","parentSelectors":["tableRow"],"selector":"a.ec-table__investment-link","multiple":false,"delay":0},{"id":"assetClass","type":"SelectorText","parentSelectors":["tableRow"],"selector":"[data-title='Asset class'] div","multiple":false,"regex":"","delay":0}]}
However, when I then use the scraped url (linkSelector) to navigate to the full factsheet and extract some detailed data from there, I lose everything but a few results - about 100 or so. (sitemap2).
{"_id":"fidelity-test2","startUrl":["https://www.fidelity.co.uk/clients/investment-finder/#?investmentType=funds&universeId=FOGBR$$ALL_3521&filtersSelectedValue={}&page=[1-7]&perPage=50&sortField=legalName&sortOrder=asc&subUniverseId=MFAC"],"selectors":[{"id":"tableBody","type":"SelectorElement","parentSelectors":["_root"],"selector":".ec-section__content--table-securities tbody","multiple":false,"delay":0},{"id":"tableRow","type":"SelectorElement","parentSelectors":["tableBody"],"selector":"tr","multiple":true,"delay":0},{"id":"keyStatsLink","type":"SelectorLink","parentSelectors":["tableRow"],"selector":"a.ec-table__investment-link","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["keyStatsLink"],"selector":"h1","multiple":false,"regex":"","delay":0},{"id":"iaSector","type":"SelectorText","parentSelectors":["keyStatsLink"],"selector":"tr:contains('Investment Association (IA) sector') td:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"ongoingCharge","type":"SelectorText","parentSelectors":["keyStatsLink"],"selector":"tr:contains('Ongoing charge (%)') td:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"txnCost","type":"SelectorText","parentSelectors":["keyStatsLink"],"selector":"tr:contains('Transaction cost (%)') td:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"perfFee","type":"SelectorText","parentSelectors":["keyStatsLink"],"selector":"tr:contains('Performance fee') td:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"performanceLink","type":"SelectorLink","parentSelectors":["keyStatsLink"],"selector":"li:Contains('Performance') a","multiple":false,"delay":0},{"id":"1yr","type":"SelectorText","parentSelectors":["performanceLink"],"selector":"#trailing-returns-table tr:nth-of-type(5) td:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"3yr","type":"SelectorText","parentSelectors":["performanceLink"],"selector":"#trailing-returns-table tr:nth-of-type(6) td:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"5yr","type":"SelectorText","parentSelectors":["performanceLink"],"selector":"#trailing-returns-table tr:nth-of-type(7) td:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"assetClass","type":"SelectorText","parentSelectors":["tableRow"],"selector":"[data-title='Asset class'] div","multiple":false,"regex":"","delay":0},{"id":"","type":"SelectorText","parentSelectors":["_root"],"selector":"","multiple":false,"regex":"","delay":0}]}
I also tried implementing the pagination via linkSelector and elementClick, but with similar results.
Any ideas?
scraper version: 0.5.4
Chrome version Version 92.0.4515.159 (Official Build) (64-bit)
Windows version Windows 10 Home 19043.1165
As an aside, I also thought that as I had already scraped the url to all 3611 factsheets I could use a 2-pass approach and put these urls into a pseudo sitemap.xml hoping to trick the sitemap xml selector into scraping each factshheet individually, but the sitemap xml selector doesn’t appear to support [file:///](file:///\) syntax, and setting up a dummy web-server to serve the dummy sitemap.xml seemed a bit OTT, especially since I'm not even sure this would work…