
So I wanted to extract contact details from a website and tried using selenium with python. I tried beautifulsoup before that. But after various searches and StackOverflow answers, it leads me to use selenium instead. But I had no luck with selenium either.
I tried using find_elements_by_css_selector and find_elements_by_xpath, but couldn't find the element. And when I try to search it using inspect element in the browser using the XPath it's visible in the search results.
Url of the website I'm trying to scrape: Unstop - Competitions, Quizzes, Hackathons, Scholarships and Internships for Students and Corporates
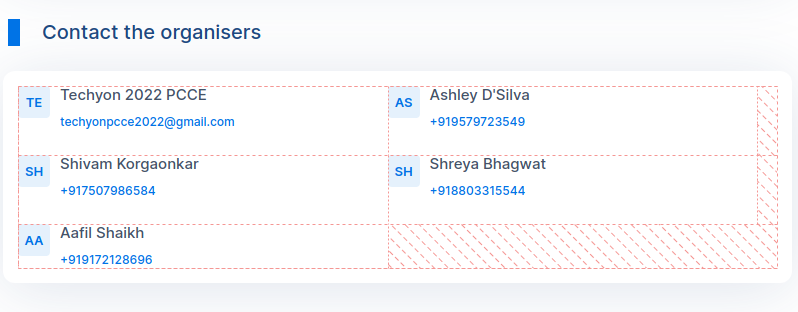
The part I'm trying to scrape: (Image below):
The situation of the code that I have written(no success):
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from webdriver_manager.chrome import ChromeDriverManager
import pandas as pd
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("https://unstop.com/hackathon/weave-the-web-powered-by-edot-solutions-techyon-2022-padre-conceicao-college-of-engineering-salcete-goa-462438")
stages = driver.find_elements_by_xpath("/html/body/div[1]/main/app-public-competition/div/div[2]/div[2]/div/div[1]/div[3]/div/app-dates-and-contacts/section/div/div[2]/ul")
print(stages)
The short Xpath of the element with class I am trying to extract:
//ul[@class='contact ng-star-inserted']
Apologies if this is a noob question, I am very new at this. Any help would be appreciated.