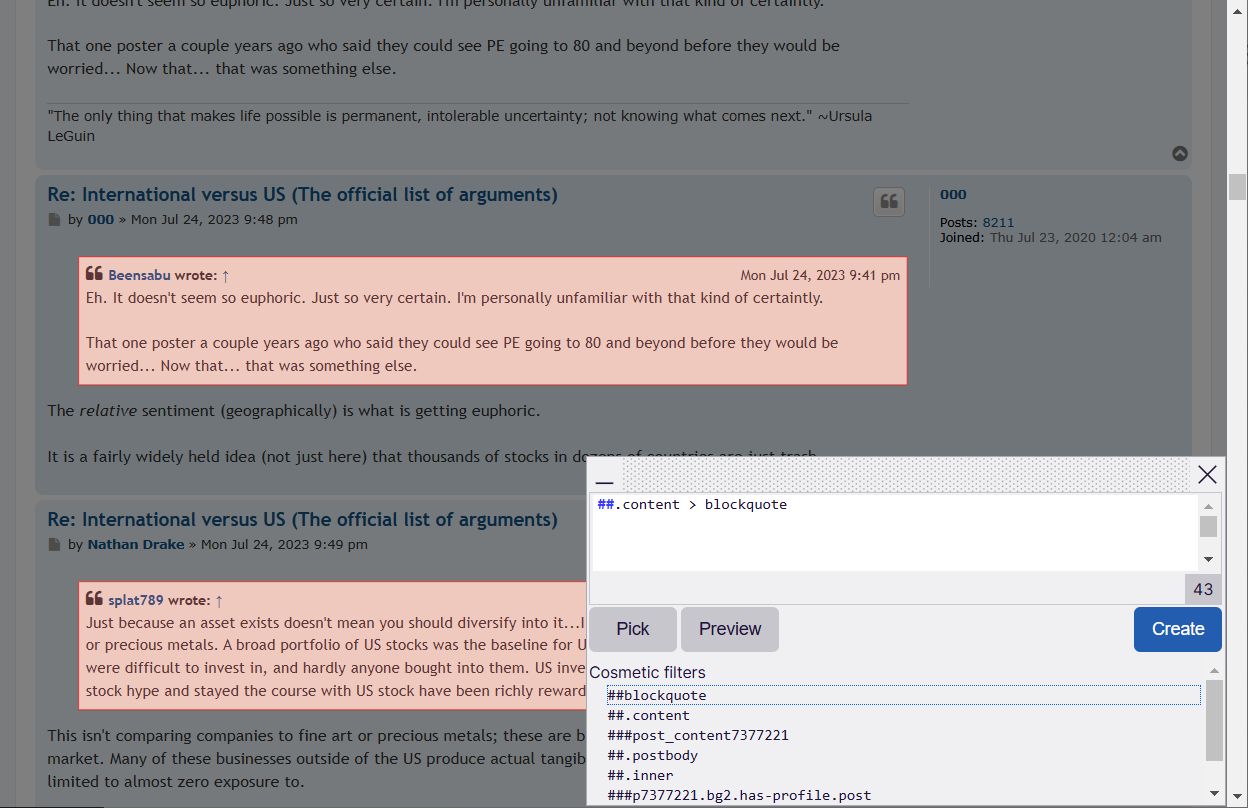
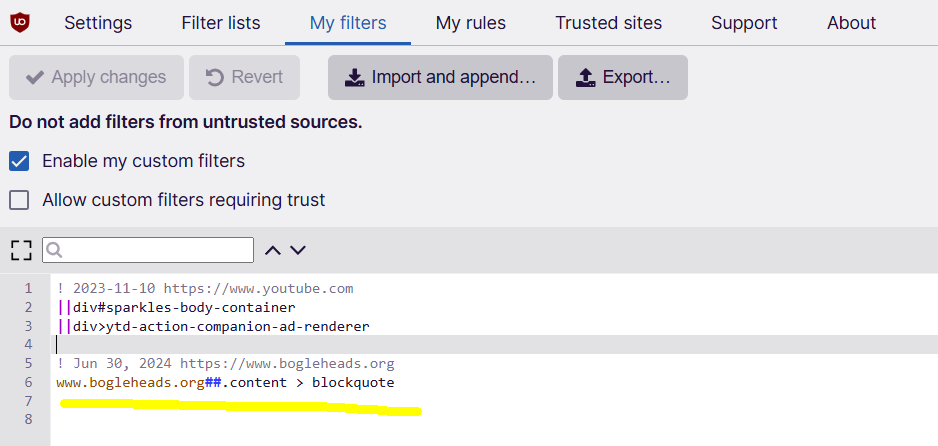
I want to scrape only the original text, not any quoted text from each post in this forum. For example, I only want to scrape the following from the first post on the URL below:
That was not Mr. Bogle's position. I don't believe he ever said that US investors would be richly rewarded by shunning int'l diversification. He often said that ex-US was unnecessary.
Int'l diversification started becoming popular in the early 1990's.
I do not want the following:
splat789 wrote: US investors who ignored the siren song of the Ex-US stock hype and stayed the course with US stock have been richly rewarded just as Jack Bogle said they would be.
I can't figure out how to exclude the quoted text (the blockquote). I have tried :not(blockquote) and > div, but neither of these work.
How can I do this?
Url: International (Non-US) versus US Equities (The "Arguments") - Page 2 - Bogleheads.org
{"_id":"bogleheads3","startUrl":["International (Non-US) versus US Equities (The "Arguments") - Page 2 - Bogleheads.orgparent:not(blockquote)","type":"SelectorText"}]}