Hi,
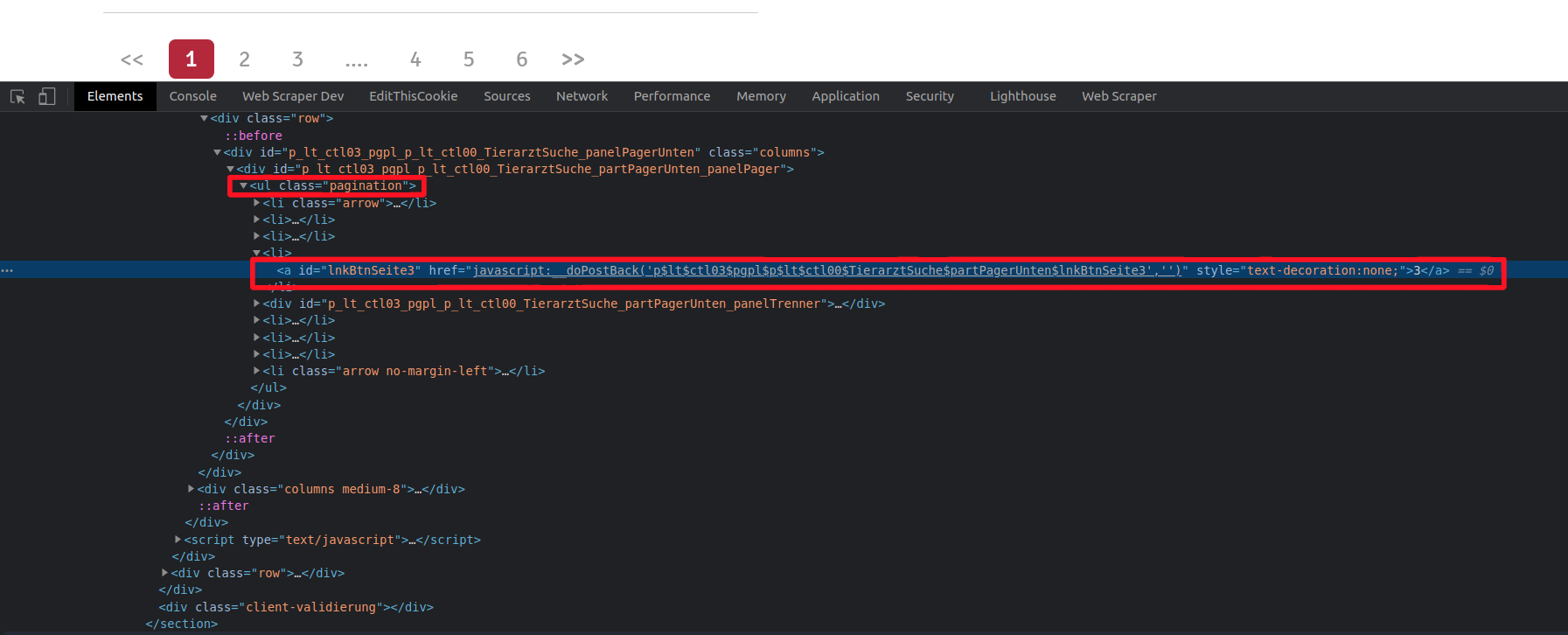
I have some trouble with the following site. When use the default delay of the element click selector, only the first page is scrapped and I get the data of 10 items of the first page. When I increase the delay (e.g. to 18000 ms (the site is not that fast)) the script loads page 1 to 3, but then suddenly stops and closes the window and does not show any data, unfortunately. What am I doing wrong? A little help would be much appreciated.
Thanks in advance.
Sitemap:
{"_id":"tasso","startUrl":["https://www.tasso.net/Service/Tieraerzte-in-Ihrer-Naehe?p=1&k=1&sl=11&li=1&po=26655&bt=53,2545<=7,9174&ent=2500#divFilter"],"selectors":[{"id":"name","type":"SelectorText","parentSelectors":["more"],"selector":"h3","multiple":false,"regex":"","delay":0},{"id":"address","type":"SelectorHTML","parentSelectors":["more"],"selector":"div.small-8","multiple":false,"regex":"","delay":0},{"id":"phone","type":"SelectorText","parentSelectors":["more"],"selector":"span.phone","multiple":false,"regex":"","delay":0},{"id":"www","type":"SelectorLink","parentSelectors":["more"],"selector":"a[target]","multiple":false,"delay":0},{"id":"category","type":"SelectorText","parentSelectors":["more"],"selector":"div:nth-of-type(4) span","multiple":false,"regex":"","delay":0},{"id":"animals","type":"SelectorText","parentSelectors":["more"],"selector":"div:nth-of-type(5) div","multiple":true,"regex":"","delay":0},{"id":"more","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"article.row","multiple":true,"delay":"18000","clickElementSelector":"a#lnkBtnNaechsteSeite","clickType":"clickMore","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"}]}