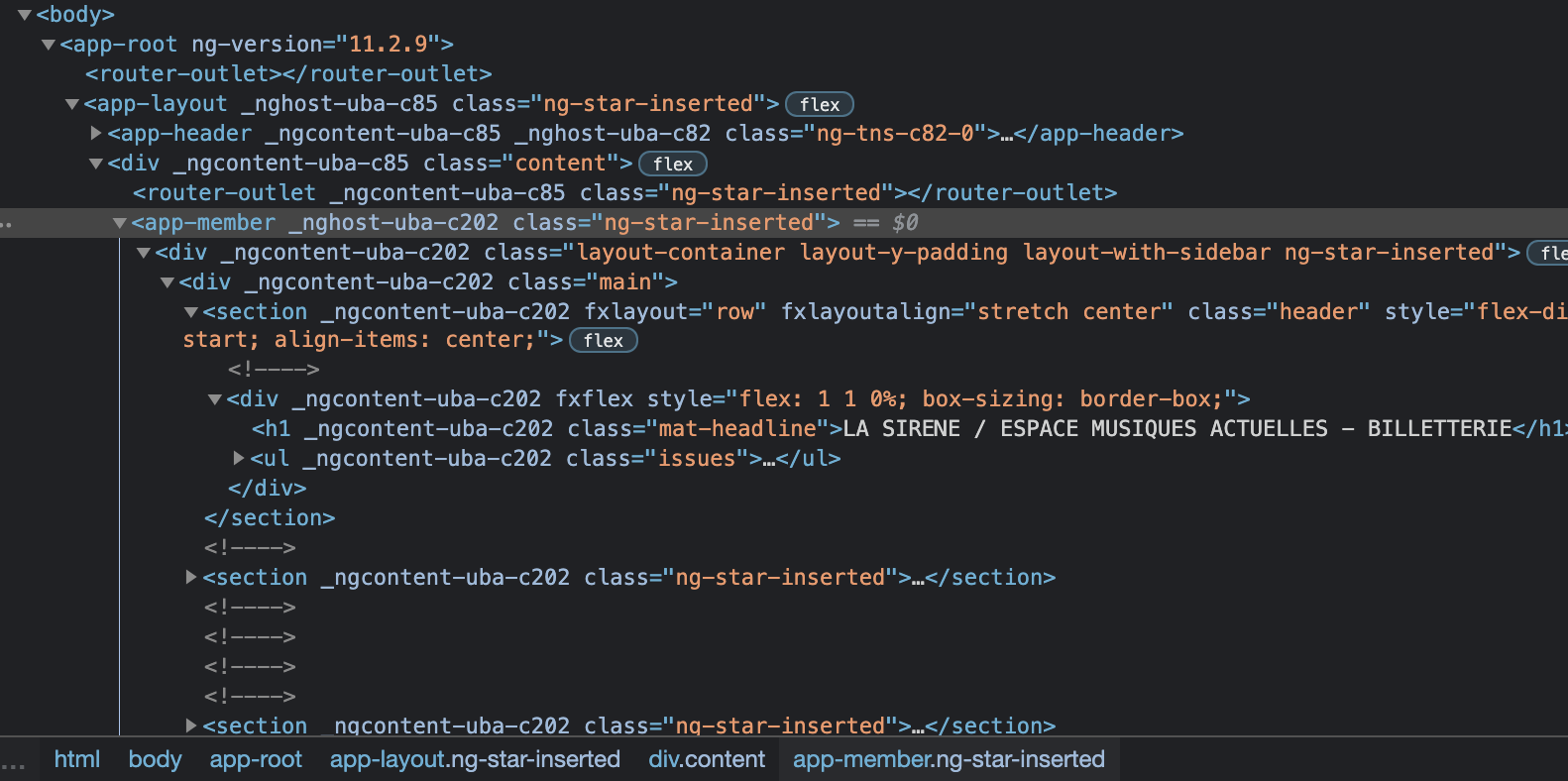
So, I'm new to Web Scraper, but have hacked around with CSS selectors in other tools that rely on them — and for the life of me can't figure out where I'm going wrong.
I'm trying to scrape a paginated directory, capturing businesses' name/description/location/website from each profile in the listing. Each item in the directory has a discrete URL, and pretty sure that I've got the initial SelectorLink tree right, and also the pagination (&page=[1-252]).
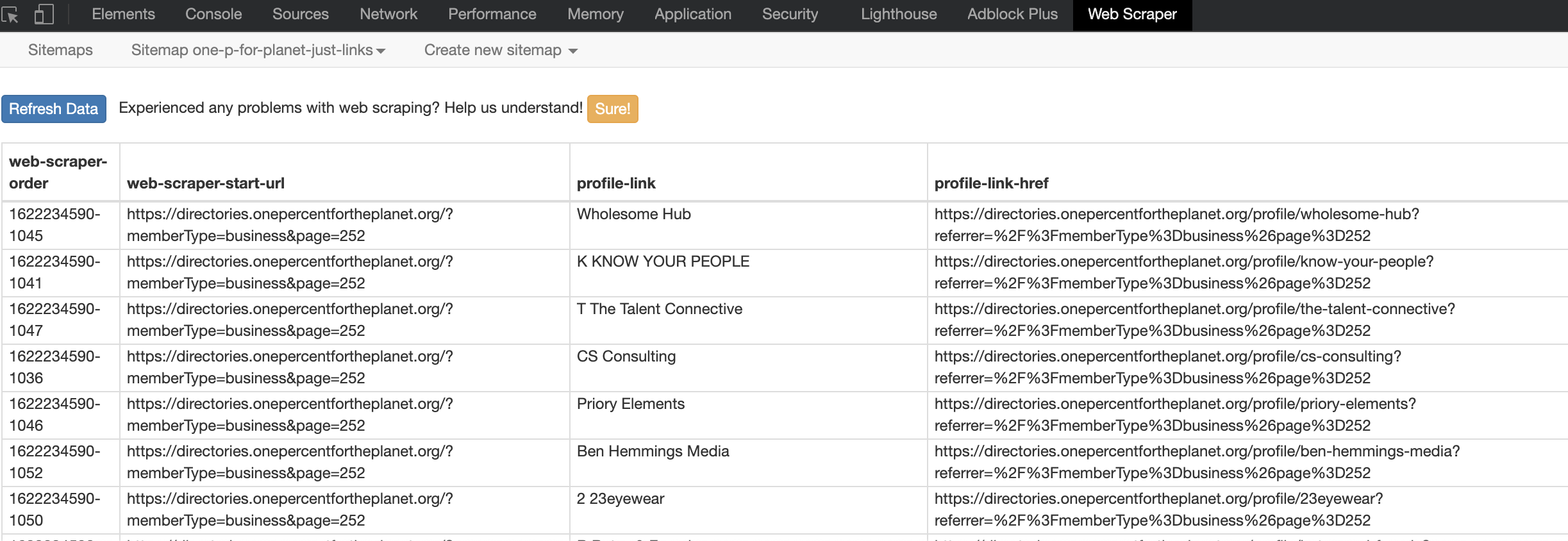
The data preview looks the way it should, and when I execute the scrape, the preview window navigates through each list item and page as it should.
But always "No data scraped yet". Tested the same tree structure on another site, and it worked fine. Thinking it might have something to do with how the elements are generated in Angular? Am I out of luck?
Url: 1% for the Planet
Sitemap:
{"_id":"one-p-for-planet-directory-biz","startUrl":["https://directories.onepercentfortheplanet.org/?memberType=business&page=252"],"selectors":[{"id":"profile-link","type":"SelectorLink","parentSelectors":["_root"],"selector":"a.mat-list-item","multiple":true,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["profile-wrapper"],"selector":"div:nth-of-type(1) > section > div > h1","multiple":false,"regex":"","delay":0},{"id":"location","type":"SelectorText","parentSelectors":["profile-wrapper"],"selector":"div:nth-of-type(2) > div> dl > dt:contains('Location') + dd","multiple":false,"regex":"","delay":0},{"id":"website","type":"SelectorText","parentSelectors":["profile-wrapper"],"selector":"div:nth-of-type(2) > div > dl > dt:contains('Website') + dd","multiple":false,"regex":"","delay":0},{"id":"profile-wrapper","type":"SelectorElement","parentSelectors":["profile-link"],"selector":"app-member","multiple":true,"delay":0},{"id":"socials","type":"SelectorGroup","parentSelectors":["profile-wrapper"],"selector":"a.social-link","delay":0,"extractAttribute":"href"}]}
 For example:
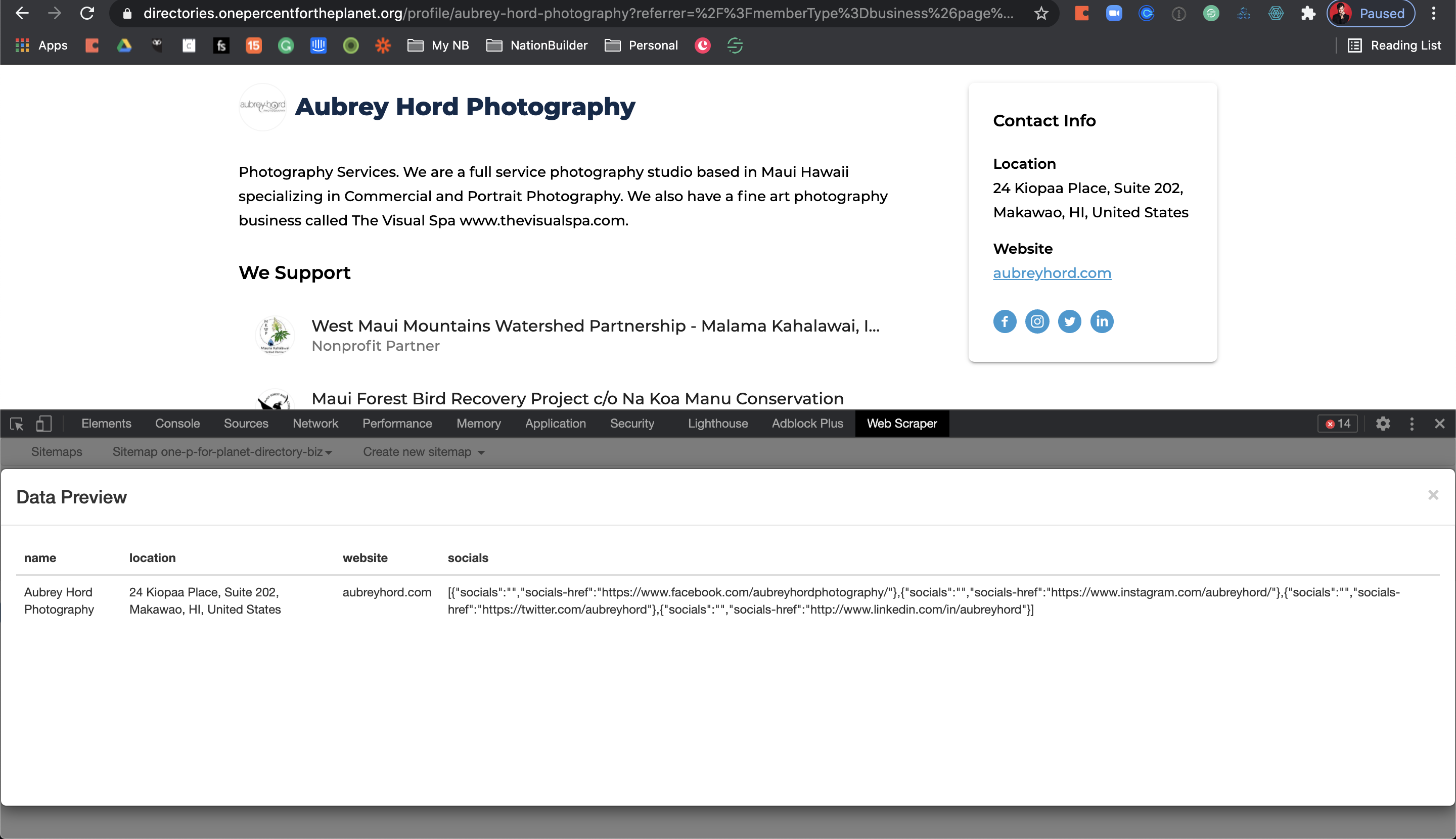
For example: