
Hello,
i'm testing out a crawler for https://www.investing.com/stock-screener.
the first id "table" works great, and the table i being identified and if i scrape, extracted correctly.
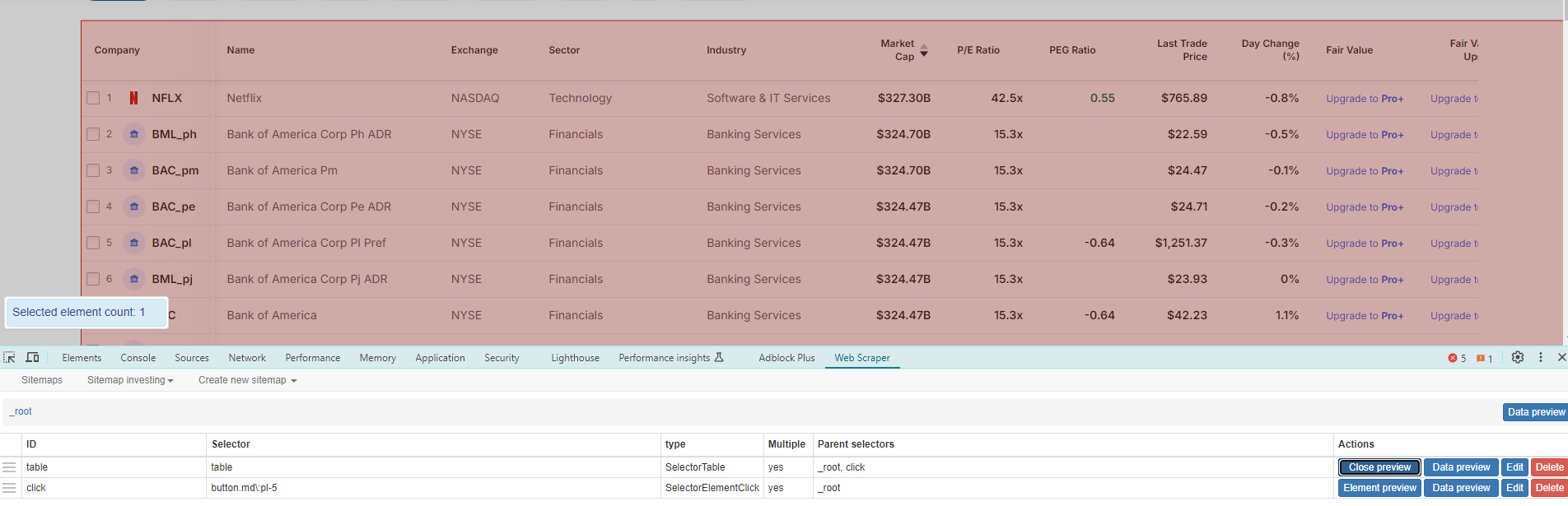
Now i added a click for next page, and i'm using the same table extractor.
the problem is that the table extractor stops working and no longer detects the table element in the website.
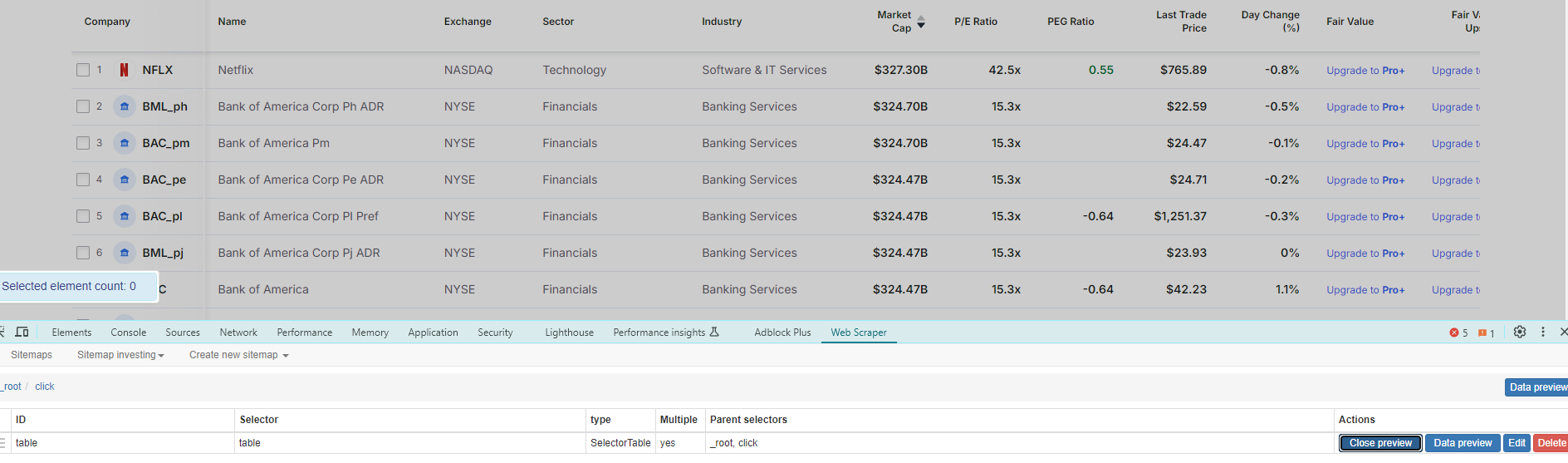
So the table extractor under "_root" finds the table element, but the same extractor under "click" finds nothing, even when testing on the same exact page.
would appreciate the help,
Thanks!